The manifestation of the action of a gene has certain characteristics.
One and the same mutant gene in different organisms can manifest its effect in different ways. This is due to the genotype of the given organism and the environmental conditions under which its ontogenesis proceeds. The phenotypic manifestation of a gene can vary according to the severity of the trait. As early as 1927, N.V. Timofeev-Resovskii proposed to call this phenomenon the expressivity of a gene. The action of a gene can be more or less constant, stable in its manifestation, or unstable, variable. Indeed, we do meet quite often with the variability of the manifestation of a mutant gene in different organisms. Drosophila has an "eyeless" mutant form (eyeless) with a highly reduced number of facets. Looking at the offspring of one parental pair, one can see that in some flies the eyes are almost completely devoid of facets, while in others the number of facets in the eyes reaches half the normal number. The same phenomenon is observed in the realization of many traits in other animals and plants.
The same mutant trait may appear in some individuals and not in other individuals of the related group. This phenomenon N.V. Timofeev-Resovsky called penetrance gene manifestations. Penetrance is measured by the percentage of individuals in a population that have a mutant phenotype. With full penetrance (100%), the mutant gene manifests its effect in each individual possessing it; with incomplete penetrance (less than 100%), the gene does not show its phenotypic effect in all individuals.
Expressiveness, like penetrance, is due to the interaction of genes in the genotype and different reactions of the latter to environmental factors. Expressiveness and penetrance characterize the phenotypic expression of a gene. Penetrance reflects the heterogeneity of lines, populations not by the main gene that determines a specific trait, but by genes - modifiers that create a genotypic environment for the manifestation of a gene. Expressiveness is the reaction of similar genotypes to the environment. Both of these phenomena can have an adaptive significance for the life of the organism and the population, and therefore the expressivity and penetrance of the gene expression are maintained natural selection... These two phenomena are very important to take into account in artificial selection.
The expressiveness of a gene in development depends on the action of environmental factors. So far, it is easiest to trace the influence of various external agents on mutant genes. Thus, in maize, mutant genes are known that determine plant dwarfism, positive geotropism (tilting plants), etc. Corresponding biochemical changes underlie the action of these genes. It is known, for example, that growth substances of the auxin type are required for normal plant growth. In the mutant dwarf form of maize, auxin is produced normally, but the dwarf gene inhibits the formation of an enzyme that oxidizes auxin, as a result of which the activity of auxin is reduced, which leads to inhibition of plant growth. If such a plant is exposed to gibberellic acid during growth, then the plant accelerates growth and becomes phenotypically indistinguishable from normal. The addition of gibberellic acid, as it were, makes up for what the normal allele of the dwarf gene would have to produce.
From this example, you can see that a gene controls the production of a specific enzyme that changes the growth pattern of a plant. Thus, knowing the mechanism of action of the mutant gene, it is possible to correct and normalize the defects it causes.
Recall that the Himalayan rabbit coloration is determined by one member of a series of multiple alleles - c 11. The usual phenotypic manifestation of this gene at normal temperature (about 20 °) is characterized by the fact that with a general white color of the coat, the tips of the paws, ears, nose and tail of the rabbit turn out to be black.

This color depends both on certain biochemical reactions taking place in the skin, associated with the production of melanistic pigments, and on the ambient temperature. The same figure shows that a rabbit raised above 30 ° C turns out to be completely white. If you pluck out a small area of \u200b\u200bwhite wool and then systematically cool it, then black wool grows on it. In this case, the effect of temperature affects the expression of the gene, affecting the production of certain enzymes.
The primrose plant has a known flower color gene, which also exhibits its effect depending on temperature. If the plants are grown at a temperature of 30-35 ° and high humidity, then the flowers will be white, and at a lower temperature, red.
Back in 1935, F.A. Smirnov studied the number of induced mutations in Drosophila: lethal, seven-year, and mutations with increased and normal viability, and found a different ratio of the listed classes under different temperature conditions. Later, the same was confirmed in the populations of Drosophila pseudoobscura. Mutants were isolated from the wild population of this species, which developed normally at a temperature of 16.5 °, at 21 ° they were semi-legal, and at 25 ° they were completely lethal. This kind of research is now being conducted on mutations in microorganisms. These mutations are called amber mutations.
The rider Habrobracon hebitor has the kidney (k) gene. It has almost 100% penetrance as lethal at 30 °, and at low temperatures of development it is almost not manifested. This type of dependence of penetrance on environmental conditions is known for most mutations in all animals, plants, and microorganisms.
The action of the same environmental factor affects different genes in different ways, and different factors affect the expression of the same gene in different ways. The study of the influence of environmental factors showed that some recessive genes, which under normal conditions in a heterozygous state are not phenotypically manifested, can appear under altered conditions.
If you find an error, please select a piece of text and press Ctrl + Enter.
GENE EXPRESSIVITY (latin expressus explicit, expressive; gene; synonym for gene expression) - the degree or measure of the phenotypic manifestation of the gene, that is, the degree and (or) the nature of the severity of the hereditary trait among individuals of a certain genotype in which this trait is manifested. The expressivity of a gene is closely related to the penetrance (see. Penetrance of the gene), or manifestation, of the gene (see), as well as to its specificity. Taken together, penetrance and expressivity characterize the variability of the phenotypic manifestation of genes.
The concept of "gene expressivity" was introduced into the scientific literature by N. V. Timofeev-Ressovsky and the German neurologist O. Vogt, who first applied it in their working togetherpublished in 1926. The need to introduce this concept was due to the fact that the term "genotype" unambiguously and uniformly defined the totality of only those genes that control some hereditary traits that do not change during the entire individual life (see Genotype). Such signs include, for example, a blood group (see Blood groups), antigens of erythrocytes and leukocytes of humans and animals (see Antigens), etc. However, more often it happens that the presence of a certain gene in the genotype is a necessary but insufficient condition for complete the similarity of the carriers of this gene for the corresponding trait. In some individuals - carriers of such a gene (in a homozygous state for recessive genes, and in a heterozygous state for dominant genes) it may not appear at all (so-called incomplete penetrance), and in some individuals in which this gene has manifested itself, its severity may be different, that is, the expressivity of this gene can vary (the so-called variable gene expression).
Varying gene expression is well known in medical genetics (see). So, the complete Marfan syndrome (see Marfan syndrome) is characterized by arachnodactyly (see), joint laxity, the formation of aneurysms of the aorta and pulmonary trunk, subluxation or dislocation of the lens, kyphosis (see), scoliosis (see), etc. However, cases of manifestation in one patient all a wedge, signs characteristic of Marfan's syndrome are rare. More often there are cases of "incomplete" Marfan syndrome, and even in one family, the symptom complex is usually not the same for different family members.
The manifestation of polymorphic groups of similar traits, which is due to different genetic reasons, should be distinguished from the varying expressivity of one gene (see Genocopy). For example, in medical genetics, a polymorphic group of forms (at least 7) \u200b\u200bof the Ehlers-Danlos syndrome is known, which is generally characterized by different combinations, localization and severity of internal bleeding caused by rupture of blood vessels, increased skin elasticity, and joint laxity. A common pathogenetic factor in all these conditions is a violation of collagen biosynthesis (see). However, with different forms of the syndrome, disorders are localized in different places of the biosynthetic collagen chain. The genetic defects that determine them are also different: four forms of Ehlers-Danlos syndrome (see Desmogenesis imperfect) are inherited in an autosomal dominant manner, two in an autosomal recessive manner, and one in a recessive type linked to the X chromosome.
The reasons for the varying gene expressivity can be interindividual genotypic differences (genotypic environment), variability in the manifestation of genes in individual development (see Ontogenesis) and the influence of environmental factors. All three causes and the interactions between them are important for the varying gene expression.
The influence of the genotypic environment on both increased and decreased gene expressivity is proved by successful artificial selection: the selection of parental pairs with a better expressed hereditary trait automatically accumulates modifier genes (see Gene) in the corresponding line that favor the manifestation of this trait, and vice versa. In a number of cases, such modifier genes have been identified. The role of the genotypic environment in varying gene expression is also evidenced by the smaller range of intrafamilial changes in the severity of hereditary traits compared to their interfamilial variability. The influence of variability in the manifestation of genes in individual development on their expressivity is illustrated by the incomplete concordance (or discordance) of genetically identical identical (monozygous) twins (see Twin method) in terms of the degree and nature of the severity of the same hereditary traits.
An example of the influence of environmental factors on gene expressivity is the different pigmentation of wool in animals of some breeds, depending on the air temperature or the improvement in the condition of patients with hereditary diseases (see) with appropriate pathogenetic treatment (for example, diet therapy, etc.).
Each of the three named reasons for the varying gene expressivity in any particular case may have a greater or lesser specific weight, but the general rule is that gene expression is determined by the interaction of genes and ontogenetic factors, as well as the influence of the environment on the organism as an integral system during ontogenesis. This concept of gene expressivity is of great theoretical importance for understanding the mechanisms of ontogenesis of living organisms and the pathogenesis of hereditary human diseases. In medical genetics, this creates the basis for the search for pathogenetic methods for correcting hereditary defects, and in the selection and cultivation of agricultural plants and animals, it helps to create new varieties and breeds and breed them under conditions optimal for better expression of economically valuable traits.
Bibliography: Bochkov N. P., Zakharov A. F. and Ivanov V. I. Medical genetics, M., 1984; Rokitskiy P. F. Field of gene action, Zh. experimental biol., ser. A, v. 5, c. 3-4, p. 182, 1929; Timofeev-Resovsky N.V. About the phenotypic manifestation of the genotype, ibid., Vol. 1, century. 3-4, p. 93, 1925; Timofeev-Resovskiy N.V. and Ivanov V.I. Some questions of phenogenetics, in the book: Actual. question modern genetics, ed. S. I. Alikhanyan, p. 114, M., 1966; Timofeef - Ressovsky N. u. Vogt O. Uber idiosomatische Variationsgruppen und ihre Bedeutung fur die Klassifikation der Krankheiten, Naturwissenschaften, Bd 14, S. 1188, 1926.
Protein synthesis largely determines body structure and function.
Structure
Humans have about 20,000 genes. Genes are found on chromosomes in the cell nucleus and mitochondria. In humans, the somatic (nongerm) cell nuclei, with a few exceptions (eg, red blood cells), typically have 46 chromosomes, organized in 25 pairs. Each pair consists of 1 chromosome from the mother and 1 from the father. 22 pairs out of 23 - and y-tosomes - are usually homologous (identical in size, shape, location and number of genes). The 23rd pair of sex chromosomes (X and Y) determines the sex of a person. Women have 2 X chromosomes (which are homologous) in the nuclei of somatic cells; in men, 1 X and 1 Y chromosome (which are heterologous). The Y chromosome contains genes that are responsible for sexual differentiation along with other genes. Since the X chromosome has many more genes than the Y chromosome, many genes on the X chromosome are not paired in males. A karyotype is a complete set of chromosomes in human cells.
Embryonic cells (eggs and spermatozoa) undergo meiosis, which reduces the number of chromosomes to 25, which is half of the number in somatic cells. In meiosis, genetic information inherited by a person from the mother and father is reunited through crossing over (exchange between homologous chromosomes). When an egg is fertilized by sperm at conception, the normal 46 chromosomes are restored.
Genes are located in a linear sequence along DNA on chromosomes; each gene has its own location, completely identical in each of the 2 homologous chromosomes. Genes that occupy the same loci on each chromosome of a pair (1 inherited from the mother and 1 from the father) are called alleles. Each gene is made up of a specific DNA sequence; The 2 alleles can have several different or different DNA sequences. The possession of a pair of identical alleles for a particular gene means homozygosity; possession of a pair of non-identical alleles is heterozygosity.
Function of genes
Genes are made of DNA. The length of a gene depends on the length of the protein that the gene encodes. DNA is a double helix in which nucleotides (bases) are paired; adenine (A) paired with thymine (T), and guanine (G) paired with cytosine (C). DNA is transcribed during protein synthesis. When DNA reproduces itself during cell division, 1 strand of DNA is used as a template from which messenger RNA (mRNA) is made. RNA has the same base pairs as DNA, except that uracil (U) replaces thymine (T). Parts of the mRNA travel from the nucleus to the cytoplasm, and then to the ribosome, where protein synthesis takes place. Transport RNA (tRNA) delivers each amino acid to the ribosome, where it is added to the growing polypeptide chain in sequence as determined by mRNA. Once the amino acid chain is assembled, it folds to create a complex 3-dimensional structure under the influence of neighboring chaperone molecules.
The DNA code is written in triplets of 4 possible nucleotides. Specific amino acids are encoded by specific triplets. Since there are 4 nucleotides, the number of possible triplets is 43 (64). Since there are only 20 amino acids, there are additional combinations of triplets. Some triplets encode the same amino acids as other triplets. Other triplets can encode elements such as an indication to start or stop protein synthesis and the order in which amino acids join and align.
Genes are made up of exons and introns. Exons encode the amino acid components in the finished protein. Introns contain other information that affects the control and rate of protein production. Exons and introns are transcribed together into mRNA, but the segments transcribed from introns are later excised. Transcription is also controlled by antisense RNA, which is synthesized from strands of DNA not transcribed into mRNA. Chromosomes are made up of histones and other proteins that affect gene expression (which proteins and how many proteins are synthesized from a given gene).
Genotype refers to the genetic makeup; it determines which proteins are encoded for production. Phenotype refers to the entire physical, biochemical, and physiological makeup of a person, i.e., how the cell (and thus the organism as a whole) functions. The phenotype is determined by the types and amount of synthesized protein, i.e. how genes are actually expressed. Gene expression depends on factors such as whether a trait is dominant or recessive, gene penetrance and expression, degree of tissue differentiation (determined by tissue type and age), environmental factors, unknown factors, and whether expression is sex-limited or subject to chromosomal inactivation or genomic imprinting. Factors that influence gene expression without altering the genome are epigenetic factors.
Knowledge of the biochemical mechanisms that drive gene expression is growing rapidly. One mechanism is intron splicing variability (also called alternative splicing). Since introns are cut out during splicing, exons can also be cut, and then exons can be assembled in many combinations, resulting in many different mRNAs being able to encode similar but different proteins. The number of proteins that can be synthesized by humans exceeds 100,000, although the human genome has only about 20,000 genes. Other mechanisms mediating gene expression include DNA methylation and histone reactions such as methylation and acetylation. DNA methylation tends to silence the gene. Histones resemble coils around which DNA is wound. Histone modifications, such as methylation, can increase or decrease the amount of proteins synthesized from a particular gene. Acetylation of histones is associated with a decrease in gene expression. A strand of DNA that is not transcribed to form mRNA can also be used as a template for RNA synthesis, which controls transcription of the opposite strand.
Traits and models of inheritance
The symptom can be as simple as eye color, or as complex as diabetes susceptibility. A single gene defect can lead to abnormalities in multiple organ systems. For example, imperfect osteogenesis (connective tissue abnormalities often caused by abnormalities in genes encoding collagen synthesis) can cause bone weakness, deafness, blueness of the eye proteins, dental dysplasia, joint hyperactivity, and abnormalities of heart valves.
Family genealogy construction. Family genealogy (family tree) can be represented as a graphical representation of inheritance patterns. It is also widely used in genetic counseling. Family genealogy uses common symbols to represent family members and related health information. Some familial disorders with the same phenotypes have multiple inheritance patterns.
Single gene defects
If expression of a trait requires only one copy of a gene (1 allele), that trait is considered dominant. If the expression of a trait requires two copies of a gene (2 alleles), that trait is considered recessive. X-linked diseases are an exception. Since males usually do not have paired alleles to offset the effects of most alleles on the X chromosome, the X allele is expressed in males, even if the trait is recessive.
Many specific diseases have been previously described.
Factors affecting gene expression
Many factors can affect gene expression. Some of these cause the expression of traits to deviate from the patterns predicted by Mendelian inheritance.
Penetrance and expressiveness. Penetrance is a measure of how often a gene is expressed. It is defined as the percentage of people who have a gene and who develop the corresponding phenotype. A gene with incomplete (low) penetrance cannot be expressed even when the trait is dominant or when it is recessive, and the gene responsible for this trait is present on both chromosomes. Penetrance of the same gene can vary from person to person and can depend on the person's age. Even when abnormal alleles are not expressed (nonpenetrance), a healthy carrier of the abnormal allele can pass it on to children who may have clinical abnormalities. In such cases, the lineage skips a generation. However, some cases of apparent nonpenetrance are due to the expert's ignorance or inability to recognize minor manifestations of the disease. It is sometimes thought that patients with minimal expression have a type of disease.
Expressivity is the limit to which a gene is expressed in one person. It can be classified as a percentage; for example, when a gene is 50% expressive, only half of the function is present, or the severity is only half of what would occur when fully expressed. Expressiveness can be influenced by the environment and other genes, so people with the same gene can change in phenotype. Expressiveness can vary even among members of the same family.
Sex-linked inheritance... A symptom that appears in only one sex is called sex-linked. Sex-limited inheritance, which may more correctly be termed sex-related inheritance, refers to the special cases in which sex hormones and other physiological differences between males and females alter the expressivity and penetrance of a gene. For example, premature baldness (known as male pattern baldness) is an autosomal dominant feature, but such baldness is rarely expressed in women, and then usually only after menopause.
Genomic imprinting... Genomic imprinting is the differential expression of genetic material depending on whether it was inherited from the father or mother. Most autosomes express both parental and maternal alleles. However, in less than 1% of alleles, expression is possible only from the paternal or maternal allele. Genomic imprinting is usually determined by effects,
which can occur in the development of gametes. Changes such as DNA methylation can be caused by the expression of certain maternal or paternal alleles to varying degrees. Disease can presumably skip a generation if genomic imprinting interferes with expression of the disease-causing allele. Defective imprinting, such as abnormal activation or silencing of alleles, can lead to disease.
Codominance... Both co-dominant alleles are observed. Thus, the phenotype of a heterozygote is different from any homozygote. For example, if a person has 1 allele coding for blood type A and 1 allele coding for blood type B, the person will have both blood types (blood type AB).
Chromosomal inactivation... In women who have more than 1 X chromosome (except eggs), all but one of the X chromosomes are inactivated; those. most alleles on the chromosome are not expressed. Inactivation occurs individually in each cell at the beginning of intrauterine life, sometimes the X chromosome from the mother is inactivated, and sometimes the X chromosome from the father. Sometimes most of the X chromosome inactivation comes from one of the parents, called skewing of the X chromosome inactivation. In any case, as soon as inactivation has occurred in a cell, all descendants of this cell have the same X-chromosome inactivation.
However, some alleles are expressed on the inactive X chromosome. Many of these alleles are found on chromosomal regions corresponding to regions of the Y chromosome (and thus are called pseudoautosomal regions, since both males and females receive 2 copies of these regions).
Unusual aspects of inheritance
Some situations present aberrant inheritance, often due to changes in genes or chromosomes. However, some of these changes, such as mosaicism, are very common, others, such as polymorphisms, are so common that they can be considered normal variations.
Mutation and polymorphism... Variations in DNA can occur spontaneously or in response to cell damage (eg, radiation, mutagenic drugs, viruses). Some of them are repaired by cellular DNA error correction mechanisms. Others are not and can be transferred subsequently to reproduced cells; in such cases, the change is called a mutation. However, the offspring can inherit the mutation only when the germ cells are affected. Mutations can be unique to an individual or family. Most mutations are rare. Polymorphism begins as a mutation. These are changes in DNA that become common in the population (prevalence over 1%) due to sufficient prevalence or other mechanisms. Most of them are stable and immaterial. A typical example is human blood groups (A, B, AB, and O).
Mutations (and polymorphisms) involve random changes in DNA. Most of them have little effect on cell function. Some alter the function of the cell, usually in a harmful way, while some are fatal to the cell. Examples of deleterious changes in cell function are mutations that cause cancer by creating oncogenes or altering tumor suppressor genes.In rare cases, a change in cell function confers a survival advantage. These mutations are likely to spread. The mutation that causes sickle cell disease confers resistance to malaria. This resistance offers the advantage of survival in areas where malaria is endemic and often fatal. However, in causing the symptoms and complications of sickle cell disease, the mutation usually also has deleterious effects when present in a homozygous state.
When and in what type of cells mutations occur, some disorders in the order of inheritance can explain. Usually, an autosomal dominant disorder is expected to be present in one or both parents of the patient. However, some disorders with autosomal dominant inheritance may reappear (in people whose parents have a normal phenotype). For example, about 80% of people with achondroplastic dwarfism do not have a family history of dwarfism. For many of these people, the mechanism is a spontaneous mutation that occurs very early in their embryonic life. Thus, other offspring are not at increased risk of impairment. However, in some of them, the disorder develops due to mutations in the germ cells of the parents (for example, an autosomal dominant gene in phenotypically normal parents). If so, other offspring are at increased risk of inheriting the mutation.
Mosaic... Mosaicity occurs when a person, starting with one fertilized egg, develops more than two cell lines that differ in genotype. Mosaicity is a normal consequence of the inactivation of the X chromosomes in women; in most women, some cells have inactive maternal X chromosomes, and other cells have an inactive paternal X chromosome. Mosaicity can also be the result of mutation. Since these changes can be passed on to subsequently created cells, large multicellular organisms have subclones of cells that have several different genotypes.
Mosaicity can be recognized as the cause of disorders in which focal changes are observed. For example, Albright's syndrome is associated with heterogeneous dysplastic changes in the bone, abnormalities of the endocrine glands, focal changes in pigmentation, and sometimes disorders of the heart or liver. The appearance of the Albright mutation in all cells could lead to early death, but people with mosaic patterns survive because normal tissue supports the abnormal tissue. Sometimes, when a parent with a monogenic disease appears to have a mild form, it is actually a mosaic; The offspring of parents are more severely affected if they receive a germ cell with a mutant allele and thus have abnormalities in each cell.
Chromosomal abnormalities are most often fatal to the fetus. Nevertheless, chromosomal mosaicity is observed in some embryos, as a result of which there are a number of chromosomally normal cells that allow offspring to be born alive. Chromosomal mosaicity can be detected by prenatal genetic testing, in particular by chorionic biopsy.
Additional or missing chromosomes... An abnormal number of autosomes usually leads to severe pathology. For example, additional autosomes usually cause disorders such as Down syndrome and other severe syndromes, or can be fatal to the fetus. The absence of an autosome is always fatal to the fetus. Chromosomal abnormalities can usually be diagnosed before birth.
Due to the inactivation of the X chromosome, having an abnormal number of X chromosomes is generally a much less serious problem than having an abnormal number of autosomes. For example, abnormalities caused by the absence of one X chromosome are usually relatively minor (for example, in Turner syndrome). In addition, women with three X chromosomes are often physically and mentally normal; only one X chromosome of the genetic material is fully active, even if the woman has more than two X chromosomes (additional X chromosomes are also partially inactivated).
Uniparental disomy... Uniparental disomy occurs when both chromosomes are inherited from only one parent.
Chromosomal translocation... Chromosomal translocation is the exchange of chromosomal parts between unpaired (non-homologous) chromosomes. If chromosomes exchange equal parts of genetic material, the translocation is called balanced. An unbalanced translocation leads to the loss of chromosomal material, usually of the short arms of two condensed chromosomes, leaving only 45 chromosomes, most people with translocations are phenotypically normal. However, translocations can cause or contribute to leukemia (acute myeloid leukemia [AML], or chronic myeloid leukemia) or Down syndrome. Translocations can increase the risk of chromosomal abnormalities in the offspring, especially unbalanced translocations. Since chromosomal abnormalities are often fatal to the embryo or fetus, parental translocations can lead to unexplained recurrent spontaneous miscarriages or infertility.
Triplet (trinucleotide) repeated violations. When the number of triplets increases enough, the gene stops functioning normally. Triplet disorders are rare, but cause a number of neurological disorders (eg, dystrophic myotonia, fragile X-oligophrenia), especially those associated with the central nervous system. Triplet repetitive abnormalities can be detected using DNA analysis techniques.
Mitochondrial DNA mutations
The cytoplasm of each cell contains several hundred mitochondria. For practical purposes, all mitochondria are inherited from the cytoplasm of the egg, so mitochondrial DNA only comes from the mother.
Mitochondrial disorders can be associated with mutations in mitochondrial or nuclear DNA (eg, deletions, duplications, mutations). High-energy tissues (eg, muscle, heart, brain) are at particular risk due to dysfunction due to mitochondrial disorders. Special mutations in mitochondrial DNA lead to characteristic manifestations. Mitochondrial disorders are equally common in men and women.
Mitochondrial disorders can be seen in many common diseases, such as some types of Parkinson's disease (involving large mitochondrial deletions in the cells of the basal ganglia) and many types of muscle disorders.
Maternal inheritance patterns characterize mitochondrial DNA abnormalities. Thus, all descendants of sick women are at risk of inheriting anomalies.
Genetic diagnostic technologies
Genetic diagnostic technology is rapidly improving. DNA or RNA can be amplified by creating multiple copies of a gene or gene segment using PCR.
Genetic probes can be used to search for specific segments of normal or mutated DNA. A known segment of DNA can be cloned and then radiolabeled or fluorescently labeled; this segment is then connected to the test pattern. The labeled DNA binds to its complementary DNA segment and can be detected by measuring the radioactivity or the amount and type of fluorescence. Genetic probes can detect a range of diseases before and after birth. In the future, genetic probes are likely to be used to screen people for many major genetic diseases at the same time.
Microarrays are powerful new tools that can be used to identify mutations in DNA, pieces of RNA, or proteins. A single chip can test 30,000 different DNA changes using just one sample.
Clinical applications of genetics
Understanding disease
Genetics has contributed to a better understanding of many diseases, sometimes allowing their classification to be changed. For example, the classification of many spinocerebellar ataxias has been changed from a group based on clinical criteria to a group based on genetic criteria.Spinocerebellar ataxias (SCA) are the main autosomal dominant ataxias.
Diagnostics
Genetic testing is used to diagnose many diseases (eg, Turner syndrome, Klinefelter syndrome, hemochromatosis). Diagnosis of genetic disorders often indicates that the patient's family should be screened for genetic defects or carrier status.
Genetic screening
Genetic screening may be indicated in groups at risk for a specific genetic disorder. The usual criteria for genetic screening are:
- known genetic inheritance patterns;
- effective therapy;
- screening tests are sufficiently reliable, reliable, sensitive and specific, non-invasive and safe.
The prevalence in a specific population must be high enough to justify the cost of screening.
One of the goals of prenatal genetic screening is to identify asymptomatic parental heterozygotes carrying the gene for recessive disease. For example, Ashkenazi Jews are screened for Tay-Sachs disease, blacks are screened for sickle cell disease, and several ethnic groups are screened for thalassemia. If the partner of the heterozygote is also the heterozygote, the couple is at risk of having a sick child. If the risk is high enough, prenatal diagnosis can be done (eg, with amniocentesis, chorionic biopsy, cord blood sampling, maternal blood sampling, or fetal imaging). In some cases, prenatally diagnosed genetic disorders can be treated to prevent complications. For example, special diets or replacement therapies can minimize or eliminate the effects of phenylketonuria, galactosemia, and hypothyroidism. Prenatal use of corticosteroids in the mother may reduce the severity of congenital virilizing adrenal hypoplasia.
Screening may be appropriate for people with a family history of a dominantly inherited disorder that appears later in life, such as Huntington's disease or cancers associated with BRCA1 or BRCA2 gene abnormalities. Screening clarifies the person's risk of developing the disease, who may accordingly schedule more frequent screening or preventive therapy.
Screening may also be indicated when a family member is diagnosed with a genetic disorder. A person who is identified as a carrier can make informed decisions about reproduction.
Treatment
Understanding the genetic and molecular basis of diseases can help guide therapy. For example, dietary restriction can eliminate toxic compounds in patients with certain genetic defects, such as phenylketonuria or homocystinuria. Vitamins or other substances can alter biochemical pathways and thus reduce toxic levels of the compound, for example folate (folic acid) lowers homocysteine \u200b\u200blevels in people with methylenetetrahydrofolate reductase polymorphism. Therapy may involve replacing deficient compounds or blocking an overactive pathway.
Pharmacogenomics... Pharmacogenomics is the science of how genetic traits affect drug response. One aspect of pharmacogenomics is how genes affect pharmacokinetics. A person's genetic makeup can help predict response to treatment. For example, the metabolism of warfarin is partly determined by gene variants of the CYP2C9 enzyme, and for vitamin K protein complex 1, epoxide reductase. Genetic changes (eg, in the production of UDP [uridine diphosphate] glucoronosyltransferase-lAl) also help predict whether the cancer drug irinotecan will have side effects.
Another aspect of pharmacogenomics is pharmacodynamics (how drugs interact with cell receptors). The genetic and, thus, receptor characteristics of the damaged tissue can help set clearer targets in drug development (eg, anticancer drugs). For example, trastuzumab can target specific cancer cell receptors in metastatic breast cancer that amplifies the HER2I neu gene. The presence of the Philadelphia chromosome in patients with chronic myelocytic leukemia (CML) helps guide chemotherapy.
Gene therapy... Gene therapy in general can be considered any treatment that alters the function of a gene. However, gene therapy for chaao is seen, in particular, as the introduction of a normal gene into cells of a person who lacks such normal genes due to a genetic disorder. Normal genes can be created using PCR from normal DNA donated by another person. Since most genetic disorders are recessive, a dominant normal gene is usually inserted. Currently, such gene insertion therapy is probably most effective for the prevention or treatment of single-gene defects such as cystic fibrosis.
One way to transfer DNA into host cells is through viral transfection. Normal DNA is inserted into the virus, which then transfects the host cells, thereby transferring the DNA into the cell nucleus. Some concerns about viral insertion include reaction to the virus, the rapid loss (inability to replicate) of new normal DNA, and damage to the viral defense by antibodies produced against the transfected protein that the immune system recognizes as foreign. Another method of transferring DNA uses liposomes, which are taken up by host cells and thereby deliver their DNA to the cell nucleus. Potential problems with liposome insertion techniques include the inability to absorb liposomes into cells, the rapid degradation of new normal DNA, and the rapid loss of DNA integration.
Gene expression can be altered by antisense technologies rather than by inserting normal genes, for example drugs can be combined with specific pieces of DNA to prevent or reduce gene expression. Antisense technology is currently being tested for cancer therapy, but is still in an experimental stage. However, it seems more promising than gene insertion therapy, because insertion success can be higher and complications can be reduced.
Another approach to gene insertion therapy is to chemically alter gene expression (for example, by altering DNA methylation). Such methods have been experimentally tested in the treatment of cancer. Chemical modification can also affect genomic imprinting, although this effect is unclear.
Gene therapy is also being studied experimentally in transplant surgery. Changing the genes of the transplanted organs to make them more compatible with the recipient's genes makes the deviation (and thus the need for immunosuppressive drugs) less likely. However, this process rarely works.
Ethical controversy in genetics
There are concerns that genetic information may be misused to discriminate (for example, by denying health insurance or employment) against people with genetic risk factors for specific diseases. Questions include the privacy of a person's own genetic information and the question of whether testing is mandatory
The idea of \u200b\u200bprenatal screening for genetic abnormalities causing serious disorders is widely supported, but there is concern that screening may also be used to select aesthetically desirable traits (eg, physical appearance, intelligence).
Cloning is highly controversial. Animal studies show that cloning is far more likely than natural methods to cause defects that are fatal or lead to serious health problems. Creating a human being by cloning is broadly unethical, usually illegal and technically difficult.
Genes? What is her role? How does gene expression mechanism work? What prospects does it open before us? How is the regulation of gene expression in eukaryotes and prokaryotes? Here is a short list of issues that will be covered in this article.
general information
Gene expression is the name for the process of transfer from DNA through RNA to proteins and polypeptides. Let's make a small digression for understanding. What are genes? These are linear polymers of DNA that are linked in a long chain. With the help, they form chromosomes. If we talk about a person, then we have forty-six of them. They contain approximately 50,000-10,000 genes and 3.1 billion base pairs. How do they navigate here? The length of the sections with which work is carried out is indicated in thousands and millions of nucleotides. One chromosome contains about 2000-5000 genes. In a slightly different expression - about 130 million base pairs. But this is only a very rough estimate, which is more or less true for significant sequences. If you work on short sections, then the ratio will be violated. It can also be influenced by the gender of the organism, the material of which is being worked on.
About genes
They come in a wide variety of lengths. For example, globin is 1500 nucleotides. And dystrophin is already as much as 2 million! Their cis regulatory elements can be removed from the gene at a considerable distance. So, in globin they are at a distance of 50 and 30 thousand nucleotides in the 5 "and 3" directions, respectively. The presence of such an organization makes it very difficult for us to define the boundaries between them. Also, genes contain a significant number of highly repetitive sequences, the functional responsibilities of which are not yet clear to us.
To understand their structure, one can imagine that 46 chromosomes are separate volumescontaining information. They are grouped into 23 pairs. One of the two elements is inherited from the parent. The "text" that is in the "volumes" was repeatedly "re-read" by thousands of generations, which introduced many errors and changes (called mutations) into it. And they are all inherited by offspring. There is now enough theoretical information to begin understanding what gene expression is. This is after all the main theme of this article.
Operon theory

It is based on genetic studies of the induction of β-galactosidase, which is involved in the hydrolytic breakdown of lactose. It was formulated by Jacques Monod and François Jacob. This theory explains the mechanism of control over protein synthesis in prokaryotes. Transcription also plays an important role. The theory is that protein genes that are functionally closely related in metabolic processes are often grouped together. They create structural units called operons. Their importance is that all genes that are included in it are expressed in concert. In other words, they can all be transcribed, or none of them can be "read". In such cases, the operon is considered active or passive. The level of gene expression can only change if there is a set of individual elements.
Induction of protein synthesis
Let's imagine we have a cell that uses carbon and glucose as its source of growth. If you change it to the disaccharide lactose, then after a few minutes it will be possible to fix that it has adapted to the conditions that have been changed. There is such an explanation for this: the cell can work with both sources of growth, but one of them is more suitable. Therefore, there is a "sight" for a more easily processed chemical compound... But if it disappears and lactose appears to replace it, then the responsible RNA polymerase is activated and begins to exert its influence on the production of the necessary protein. This is more of a theory, but now let's talk about how gene expression actually occurs. This is very exciting.
Organization of chromatin

The material in this paragraph is a model of a differentiated cell of a multicellular organism. In the nuclei, chromatin is packed in such a way that only a small part of the genome (about 1%) is available for transcription. But despite this, thanks to the variety of cells and the complexity of the processes going on in them, we can influence them. At the moment, the following influence on the organization of chromatin is available to humans:
- Change the number of structural genes.
- Effectively transcribe different sections of code.
- Rearrange genes on chromosomes.
- Modify and synthesize polypeptide chains.
But effective expression of the target gene is achieved as a result of strict adherence to technology. It doesn't matter what you are working with, even if the experiment is on a small virus. The main thing is to adhere to the prepared intervention plan.
Changing the number of genes
How can this be done? Imagine that we are interested in the effect on gene expression. We took eukaryote material as a prototype. It has high plasticity, so we can make the following changes:
- Increase the number of genes. It is used when it is necessary for the body to increase the synthesis of a certain product. Many useful elements of the human genome (for example, rRNA, tRNA, histones, etc.) are in this amplified state. Such regions can have a tandem arrangement within the chromosome and even go beyond them in the amount from 100 thousand to 1 million base pairs. Let's take a look at a practical application. The gene of metallothionein is of interest to us. Its protein product can bind heavy metals like zinc, cadmium, mercury and copper and, accordingly, protect the body from poisoning by them. Its activation can be useful for people who work in unsafe conditions. If a person has an increased concentration of the previously mentioned heavy metals, then the activation of the gene occurs gradually automatically.
- Reduce the number of genes. This is a rather rarely used method of regulation. But examples can also be given here. One of the most famous is erythrocytes. When they mature, the nucleus is destroyed and the host loses its genome. Lymphocytes and plasma cells of various clones undergo a similar process during maturation, which synthesize secreted forms of immunoglobulins.
Rearrangement of genes

The important thing is the ability to move and combine the material, in which it will be capable of transcription and replication. This process is called genetic recombination. By what mechanisms is it possible? Let's look at the answer to this question using the example of antibodies. They are created by B-lymphocytes that belong to a particular clone. And if an antigen enters the body, for which there is an antibody with a complementary active center, their attachment will occur, followed by cell proliferation. Why does the human body have the ability to create such a variety of proteins? This possibility is provided by recombination and But this may also be a consequence of artificial changes in the DNA structure.
RNA change
Gene expression is a process in which it plays a significant role. If we consider mRNA, then it should be noted that after transcription, the primary structure can change. The sequence of nucleotides in genes is the same. But in different tissues of mRNA, substitutions, insertions can appear, or simply pairings will occur. As an example from nature, one can cite apoprotein B, which is created in the cells of the small intestine and liver. What's the difference between editing? The gut version has 2152 amino acids. Whereas the liver variant boasts 4563 residues! And despite this difference, we have exactly apoprotein B.
Changes in mRNA stability

We've almost reached the point where we can deal with proteins and polypeptides. But before that, let's look at how the stability of mRNA can be fixed. To do this, initially it must leave the nucleus and leave the cytoplasm. This is done due to the existing pores. A large amount of mRNA will be cleaved with nucleases. Those that avoid this fate organize complexes with proteins. The lifetime of eukaryotic mRNA varies over a wide range (up to several days). If the mRNA is stabilized, then at a fixed rate it will be possible to observe that the amount of newly formed protein product increases. This will not change the level of gene expression, but, more importantly, the body will act more efficiently. With the help, you can code the final product that will have a significant life span. So, for example, it is possible to create β-globin, functioning for about ten hours (for him this is quite a lot).
Process speed

So, in general, the system of gene expression is considered. Now it remains only to supplement the existing knowledge with information about how quickly the processes occur, as well as how long proteins live. Let's put it this way, let's control gene expression. It should be noted that the effect on rate is not considered to be the main way of regulating the diversity and amount of the protein product. Although its change to achieve this goal was still used. An example is the synthesis of a protein product in reticulocytes. Hematopoietic cells at the level of differentiation are devoid of a nucleus (and hence DNA). The levels of regulation of gene expression are generally built depending on the ability of some compound to actively influence the processes being carried out.
Duration of existence
When a protein is synthesized, the time during which it will live depends on the proteases. It is impossible to name the exact terms here, since the range in this case is from several hours to a couple of years. The rate at which a protein is broken down varies widely depending on which cell it is in. Enzymes that can catalyze processes tend to be "consumed" quickly. Because of this, they are also created by the body in large quantities. Also, the physiological state of the body can affect the lifespan of a protein. Also, if a defective product was created, it will be quickly eliminated by the protective system. Thus, we can confidently say that the only thing we can judge about is the standard lifetime obtained in laboratory conditions.
Conclusion

This direction is very promising. For example, the expression of foreign genes can help cure hereditary diseases as well as eliminate negative mutations. Despite the extensive knowledge on this topic, we can confidently say that humanity is still at the very beginning of the path. Genetic engineering has recently learned to isolate the necessary sections of nucleotides. 20 years ago, one of the greatest events of this science happened - Dolly the sheep was created. Research is currently underway with human embryos. It is safe to say that we are already on the threshold of a future where there are no diseases and physiological suffering. But before we get there, we need to do a very good job for the prosperity.
The action of genes (expression, expression of genes) is understood as their ability to control the properties of organisms or, more precisely, the synthesis of proteins. The action of genes is characterized by a number of features, the most important of which is their expressivity. Expressivity is understood as the degree of phenotypic expression of genes, that is, the "strength" of the action of genes, manifested in the degree of development of the traits they control. The term was proposed by N.V. Timofeev-Ressovsky (1900-1981). Expressiveness of genes is not a permanent property of heredity, because it is very variable in plants, animals and humans. For example, people manifest in different ways such a trait as the ability to taste phenylthiocarbamide. For some, this substance is too bitter, for others, its bitterness seems less, which is a result of the different degrees of expressiveness of the gene that controls the ability to taste this compound. An example of the variability of gene expression is also the expressiveness of the dominant gene that controls juvenile cataract of human eyes. The expression of this gene in different individuals varies from a slight opacity of the lens of the eyes to its complete opacity.
On the other hand, the action of genes in mammals is characterized by the so-called genomic imprinting,consisting in the fact that two alleles of a gene are expressed differentially, ie, only one allele of two alleles (paternal and maternal) is expressed, inherited from the parents. For example, in humans, the gene for insulin-like factor 2 is normally expressed only from the allele inherited from the father, while the adjacent gene encoding untranslated RNA is expressed only from the allele inherited from the mother.
The most important feature of the action of genes is also their penetrance, which was also first described by N.V. Timofeev-Resovsky. It is understood as the frequency of manifestation of a particular gene, measured by the frequency of occurrence of a trait in a population. This is explained either by the modifying influence of other genes, or by the environment, or by the combined action of these factors. Taking into account nature expressively
of gene penetrance and penetrance is of great practical importance, especially in medical genetics.
Organisms inherit from their parents not traits or properties, they inherit genes. In accordance with existing concepts, the action of genes through RNA leads to the formation of proteins. Therefore, proteins are the end products of gene action, the result of gene expression. In other words, genes control protein synthesis. Since genes are DNA, the question boils down to the following: how does DNA perform its functions in controlling protein synthesis? The answer to this question is that DNA contains genetic information about protein synthesis, that is, it contains a genetic code, which is understood as a system for recording genetic information about protein synthesis in DNA molecules. The implementation of the genetic code occurs in two stages, one of which is called transcription, and the second is called translation. The flow of information follows the DNA - RNA - protein scheme. This scheme is called the central dogma of biology.
STRUCTURE AND PROPERTIES OF THE GENETIC CODE
The structure of the genetic code is characterized by the fact that it is triplet, that is, it consists of triplets (triplets) of nitrogenous bases, called codons. One codon codes for the location of one amino acid in the polypeptide chain (Table 13). As for the properties of the genetic code, it is non-overlapping, linear, without punctuation ("commas"), providing free spaces between codons, and degenerate.
Non-overlapping of the genetic code means that any nitrogenous base is a member of only one codon. No nitrogenous base is included in two codons simultaneously. For example, in the sequence AAGAUAGZA there are three codons AAG, AUA, HCA, but not AAG, AHA, GAU, etc. (Fig. 49).
Codons in the form of triplets of nitrogenous bases follow without interruption. There are no free spaces between codons.
The degeneracy of the code is due to the fact that the same amino acid can be encoded simultaneously by several codons. This applies to all amino acids except methionine and tryptophan, which correspond to single codons. Finally, gene transcription (reading of triplets of nitrogenous bases)
starts at a fixed point of the gene and ends also at a fixed point.
Table 13.Genetic code
codes | Antikdon | Amino acid | By code | Anticodon | Amino acid |
|
UUU UUTS УУА УУГ ЦУЦ ЦУУ ЦУА ЦУГ AUU AUC AUA AUG goo GUTS GUA Gug ush UCU USH uCG CCU CCH GAA GAG USU USH UGG | AAG Π AAG J aad -1 aats GAG GAU GATS UAG UAC TsAG TsAU ap ASU fri GSU TSUE ~ TSU5 ACG 2 AShchD | Fenklalvnin Leucine Iaoleucine Motionine Sluggish Cerkne Proline Gldamiaoic acid Tsnstenn Tryptophan | ACU ACC ACA ACG GTSU psh gtsa SHG UAU UAC UAA ~ | UAG UGA J tsau TsAC tsaa tzag AAU aats ALA AAG GAU GATS tsgu TsGTs Tsgl PCS ΑΓΑ AGG GGU GSH GGA YGG | USU J cpu η cpu CSU J art] stop good goo] yyr ^ j UUYA "Ί UUA J train - ί MCC J GSh psch UCU _ CCG CCU shsh | Alanya Threonine Tiroain Pistndin Glutamnn Asparalsh Liaii Aashraginic * acid Arpganv Glycine |
|
I - inosine (hypoxanthine nucleoside); R is pseudouridine; V is 5-carboxymethoxyuridine; D - unidentified guanosine derivative; E is 5-metolalaninomethyl-2-thiouridine; S is 5-methoxycarbonylmethyl-2-thiouridine; A - adenine; C - cytosine;
G - guanine
Figure: 49.Properties of the genetic code
TRANSCRIPTION
The bridge between the gene (codons) and the protein is provided by RNA. More precisely, the information encoded in the DNA base sequence is first transferred from DNA to messenger RNA (mRNA). This stage of information transfer is called transcription and occurs in prokaryotes in the nucleoid, and in eukaryotes in the nucleus.
Transcription is the first stage in the transfer of genetic information, the essence of which is the synthesis of mRNA, ie, in the "rewriting" of genetic information into mRNA molecules. The main structures involved in transcription are the DNA template (DNA strand), RNA polymerase, and chromosomal proteins (histone and non-histone).
However, along with mRNA molecules, RNA molecules of other species (ribosomal and transport), which are also important in the implementation of genetic information, are transcribed with DNA. All these RNAs are also called nuclear. The sizes of the transcribed RNA molecules depend on the signals of the start and stop of synthesis (initiation and termination codons) sent from the DNA template strand.
The most abundant RNA in cells of all types are molecules of ribosomal RNA (rRNA), which play the role of structural components of ribosomes. In eukaryotes, rRNA synthesis is controlled
a huge number of genes (hundreds of copies) and occurs in the nucleolus. In human cells, genes for rRNA are localized on chromosome pairs 13, 14, 15, 21, and 22. RRNA molecules are products of primary transcript processing (propRNA). Transport RNA (tRNA) molecules that are involved in decoding information (translation) are found in cells in smaller quantities.
MRNA molecules make up about 3% of the total cellular RNA, they are very unstable. Their half-life is unusually short in prokaryotes, amounting to 2-10 minutes. In eukaryotes, the half-life of mRNA molecules is several hours or even several weeks. In prokaryotes, mRNA molecules are the direct products of transcription. In contrast, in eukaryotes, they are products of the processing of primary RNA transcripts.
The synthesis of mRNA molecules occurs in the cell nucleus, from where they pass through the nuclear membrane into the cytoplasm to the ribosomes. It is very similar to DNA replication. The only difference is that only one DNA strand is used as a template (template) for copying the mRNA strand. In this case, copying of mRNA can begin from any point on a single DNA strand. It is important to emphasize that a gene is transcribed from only one strand. At the same time, even two adjacent genes can be transcribed from different strands. Thus, either of the two strands of DNA can be used for transcription. One of the strands is transcribed by some RNA polymerases, the other - by other RNA polymerases. Since both DNA strands have opposite polarity, transcription on each of the strands takes place in opposite directions. The strand that contains the same sequences as the mRNA is called the coding strand, and the strand that provides the synthesis of mRNA (based on complementary pairing) is called the anti-coding strand. Due to the reading of the code from the mRNA, bases A, G, Y, C are used to write it.
In smaller quantities, transport RNA (tRNA) molecules are found in cells, which are involved in decoding information (translation).
The tRNA molecules are also products of primary transcript processing (see below). An essential feature of tRNAs is the folded character of their secondary structure, which has the shape of a clover leaf (Fig. 50).

Figure: 50.Secondary structure of the phenylalanine tRNA molecule
All RNA is transcribed from DNA that carries multiple copies of the corresponding genes. The RNA synthesis mechanism is similar to the DNA replication mechanism. The immediate precursors in RNA synthesis are ribonucleoside tri-phosphates, and the same base pairing rule applies here, except that only limited segments of the DNA chain are encoded and that thymine in DNA is replaced by uracil. Uracil pairs with adenine in the same way as thymine. The RNA chain grows in the direction from the 5 "- to the 3" end with the release of pyrophosphate (Fig. 51).
Figure: 51. Transcription in eukaryotes
RNA synthesis is provided by RNA polymerases. In prokaryotes, the synthesis of mRNA, rRNA and tRNA is carried out by only one type of RNA polymerase, the number of molecules of which in cells reaches 3000. Each of the molecules of this RNA polymerase consists of six polypeptides, which

subunits β and β "(m.m. 155,000 and 151,000, respectively), two subunits of α m.m. 36,000 and two more low-molecular subunits δ and ω, initiation of transcription is provided by a complex polymerase + proteins(about 6 protein complexes). Binding of RNA polymerase to DNA occurs at a site called a promoter. Have E. colithe promoters contain the TATAAT sequence (Pribnau box) and are controlled by a protein factor (Fig. 52).
In contrast, in eukaryotic cells, there are three RNA polymerases, which are complex molecules containing from one to several polypeptide chains. Each of these RNA polymerases, by attaching to a promoter on DNA, ensures the transcription of different DNA sequences. RNA polymerase I synthesizes ribosomal RNA (the basic RNA molecules of the large and small ribosomal subunits). RNA polymerase II synthesizes all mRNA and a part of small rRNA, RNA polymerase III synthesizes tRNA and RNA 5/5 "-subunits of ribosomes.

Figure: 52.Selection of promoters
Eukaryotic RNA polymerases are also characterized by a complex structure. RNA polymerase II of many organisms is built from 12 different polypeptides, three of which are homologous to subunits β", β and α RNA polymerases from E. coli,RNA polymerases I and III have 5 subunits similar to those of RNA polymerase II. RNA polymerase II initiates transcription, and this requires the protein DNA helicase, which is determined by the RA 25 gene in yeast and by the XRB gene in humans.
As noted above, transcription in eukaryotes is a more complex process than in prokaryotes. mRNA of eukaryotes forms -
in the nucleus from primary gene transcripts of 1000-500,000 base pairs as a result of processing (Fig. 53). In other words, the formed primary transcripts (pro-mRNA) are not capable of translation throughout their entire length. In order for the pro-mRNA to become a "mature" mRNA, which is fully translated, it is involved in processing even in the nucleus, which consists in the fact that untranslated regions (introns) are "cut out" from the promRNA, after which the translated regions (exons) are reunited ( splicing - processing). As a result, continuous sequences are formed, ie, molecules of "mature" mRNA, which are much smaller in size than pro-mRNA molecules. The biological mechanisms of splicing are determined by the participation in this process of small nuclear ribonucleoprotein particles, which are concentrated in the interphase nucleus together with ribonucleoprotein splicing factors. The intracellular distribution of splicing factors is controlled by one of the kinases. The four RNA processing reactions are catalyzed by RNA enzymes (ribozymes).
In addition to the modification of nuclear pro-mRNA by “cutting out” and splicing of its segments, so-called “editing” of RNA sometimes takes place, which consists in the conversion of one base to another. For example, in liver cells, the synthesized protein apolidoprotein has a molecular weight of about 242,000 daltons. This is the result of a conversion in the coding gene of cytosine to uracil (in intestinal cells), which leads to the formation of stop-
Figure: 53.RNA processing

codon and therefore a shorter protein. Finally, RNA modification is also possible by post-transcriptional addition to the 3 "end of 30-50 nucleotides of polyadenylic acid at a distance of 15 nucleotides from the AAAAA sequence. For this reason, transcription ends far from the polyA signal, and processing removes extranucleotides before polyA addition.
The synthesized "mature" mRNA is the primary product of gene action and then goes from the nucleus to the cytoplasm, where it serves as a matrix for the formation of polypeptide chains on ribosomes. It is believed that cells contain 2000-3000 mRNA molecules at different levels of synthesis and decay. In particular, ribozymes with polynucleotide kinase activity have been identified that can catalyze ATP-dependent phosphorylation.
Most eukaryotic promoters contain a TATA sequence located at a distance of 30 bases from the transcriptional start site. Transcription is initiated by the combined action of polymerase and 6 additional proteins.
The identification of introns raised the question of their origin. In explaining the origin, two hypotheses are used. According to one hypothesis, introns were already present in ancestral genes, according to another, introns were included in genes that were originally contiguous.
Along with the described transcription in some RNA viruses, reverse transcription is known, in which the template for DNA synthesis is RNA and which is carried out by an enzyme called reverse transcriptase (reverse transcriptase).
Here information follows the RNA - DNA - protein scheme. Studies show that reverse transcriptase is found in both prokaryotes and eukaryotes. It is believed that revertase has a very ancient origin and existed even before the division of organisms into prokaryotes and eukaryotes.
Broadcast
Broadcast is important component general metabolism, and its essence lies in the translation of genetic information from mRNA, which is the primary product of the action of genes, into the amino acid sequence of proteins (Fig. 54). Broadcast
occurs in the cytoplasm on ribosomes and is a very complex, but central process in protein synthesis, in which, in addition to ribosomes, mRNA, 3-5 rRNA molecules, 40-60 molecules of different tRNAs, amino acids, about 20 enzymes (aminoacyl tRNA synthetases) that activate amino acids are involved , soluble proteins involved in the initiation, elongation and termination of the polypeptide chain.

Figure: 54. Broadcast
Ribosomes are made up of half protein and half rRNA (3-5 molecules for each ribosome). The sizes of ribosomes are expressed in units of sedimentation rate during centrifugation. In prokaryotes, the size of ribosomes is 70 S, in eukaryotes - 80 S. Ribosomes are built from a pair of subunits (large and small), which dissociate upon completion of mRNA translation. Have E. colithe large subunit (50 S) contains two rRNA molecules (5 S and 23 S) and 30 polypeptides, while the small subunit (30 S) - one rRNA molecule (16 S) and 19 polypeptides. Eukaryotes have a large
the subunit contains three different rRNA molecules (5 S, 5.8 S and 28 S) while the small subunit contains one rRNA molecule (18 S).
Transport (adapter, soluble) RNAs are small (5 S) molecules 75-80 nucleotides long. The tRNA nucleotides are built from a phosphoric acid residue, a carbon moiety (ribose), and a base. The main nucleotides of tRNA are adenyl, guanyl, cytidyl, and uridyl. At the same time, one of the features of the tRNA structure is that they all contain several unusual, so-called minor nucleotides, the latter being chemical modifications of adenyl, guanyl, cytidyl, and uridyl nucleotides (mainly in the form of methylated pturines or nucleotides with methylated ribose). Some of these minor nucleotides are found in the same region in different tRNAs. tRNAs attach free amino acids to themselves and transfer (include) them into the forming chains of polypeptides. Each tRNA is capable of attaching and transferring only one amino acid, but for each amino acid there are 1-4 tRNA molecules.
All tRNAs are characterized by a specific nucleotide sequence. They contain triplets of nucleotides called anticodons, which are complementary to mRNA codons. Anticodons are located at the center of the tRNA. There are 55 known anticodons.
The first stage of translation occurs in the cytoplasm and consists in combining each amino acid with ATP and a specific enzyme, aminoacyl-tRNA synthetase. As a result, a bond is established between the phosphate and the carboxyl group of the amino acid (—P — O — C), which leads to the formation of complexes consisting of the amino acid, AMP, and a specific enzyme. Pyrophosphates are removed during the formation of these complexes (Fig. 55).
The second stage of translation is also carried out in the cytoplasm. Since aminoacyl-tRNA synthetases recognize amino acids and their tRNA, the second stage consists in the interaction of the formed amino acid-AMP-specific enzyme complexes (aminoacyl-tRNA synthetase) with specific tRNAs (one complex - one tRNA). Since the chains of all tRNAs have the same end structure (the final base is adenine, and the two previous ones are cytosine and cytosine), the binding of one amino acid to a specific tRNA occurs by establishing a connection between

the ribose of the terminal nucleotide (adenylic acid) and the carboxyl group of the amino acid (—C — O — C—). As a result of this interaction, the formation of the so-called aminoacyl-tRNA occurs, which are complexes of an amino acid with a specific tRNA, and the release of AMP and an enzyme (aminoacyl-tRNA synthetase) during the formation of these complexes. Therefore, aminoacyl-tRNA are direct precursors of polypeptide synthesis on ribosomes.
The implementation of these two steps leads to the activation of amino acids. Some synthetases activate the 2 "-hydroxyl of the terminal base of tRNA, while others activate 3" -hydroxyl, and some
activate both 2 "- and 3" -hydroxyls. However, these differences are irrelevant, since after release, the amino-social group on tRNA migrates back and forth.
The third stage of translation consists in decoding the mRNA. It is carried out on ribosomes and involves both mRNA and various aminoacyl-tRNAs. After mRNA has departed from DNA and passed through the nuclear membrane into the cytoplasm, it attaches to an RNA sequence smaller than the 30 S-subunit of the ribosome. An mRNA sequence that binds to the rRNA sequence of the ribosomal subunit 30 S,received the name of the ribosome-binding site or the Shaino-Dalgarno sequence. Meanwhile, each ribosome has two tRNA-binding sites. Website AND,or an aminoacyl (acceptor) site that binds the incoming aminoacyl-tRNA that carries the amino acid to be added to the growing polypeptide chain adjacent to the previously added amino acid. Website R,or a peptide (donor) site that binds a peptidyl-tRNA to which the growing polypeptide is attached. The specificity of binding of aminoacyl-tRNA at these sites is provided by the mRNA codons, which are part of the sites ANDand R.This binding occurs due to hydrogen bonds established between the specific bases (anticodon) of each aminoacyl-tRNA and the base (codon) of the corresponding mRNA sequence. The first and second bases of the codon always pair with the third and second (respectively) bases of the anticodon, while the third base of the codon, if it is uracil, pairs with guanine or anticodon hypoxanthine, if it is adenine, then with anticodon hypoxanthine, and if guanine - then with uracil anticodon. As already noted, the interaction of mRNA with tRNA is supported by
rRNA 16 S.
After binding to mRNA, aminoacyl-tRNA is placed (included) amino acids along the mRNA molecule and the sequence corresponding to the sequence of triplets of nitrogenous bases in the mRNA. The extension of the polypeptide chain is ensured by the fact that during protein synthesis, ribosomes (polysomes) move along the mRNA chain. At the same time, peptide bonds are formed, which is provided by several transferase enzymes, one of which simultaneously catalyzes the binding of aminoacyl-tRNA to the ribosome, which occurs in the presence of GTP as a cofactor. Each
the peptide bond is formed by covalently linking the carboxyl carbon atom of the first amino acid to the amino group of the second amino acid. In this case, in the process of binding, the tRNA of the first amino acid is detached from the carbon of the carboxyl group of its amino acid. Each newly added amino acid is in place following the previously added amino acid. As you can see, the polypeptide chain is extended from the carboxyl end, and amino acids are added sequentially. The translation is carried out in the direction from the 5 "- to the 3" end of the polypeptide type.
tRNAs are characterized by extremely high specificity, which is manifested in their anticodon sequences corresponding to codons, the availability for recognition of the desired aminoacyl-tRNA synthetase, and the exact binding to the sites ANDand Ron ribosomes.
The initiation, elongation and termination of polypeptide synthesis are under genetic control.
Along with the codons that determine the sequence of amino acids, there are codons that determine the beginning and end of mRNA reading. An essential role in protein synthesis belongs to the N-terminal amino acid formylmethionine and its tRNA. N-formylmethionine-tRNA (CHCNH-CH (CH 2 -CH 2 SCH 3) -COOtRNA) is formed as a result of the formylation of the α-amino group of methionine NH 2 CH (CH 2 CH 2 SCH 3 CO) OH in methionyl-tRNA. Since formylation is characteristic only of methionine and is catalyzed by the enzyme transformylase, it is believed that formylmethionine-tRNA is the initiator of polypeptide synthesis. This means that all polypeptides in the synthesis process begin with methionine. VV-formylmethionine is the / Y-terminal amino acid of all proteins.
Initiation of the polypeptide chain begins with the formation of a complex between mRNA, formylmethionine-tRNA, and a ribosomal unit 30 S,which is provided by factors (proteins) of initiation 1F1, 1F2and 1F3, as well as GTP. This complex combines with the 50 ^ -ribosomal unit, as a result of which formylmethionin tRNA becomes bound to the peptidyl site. The energy for this is provided by the hydrolysis of one GTP molecule. The codons AUG, GUA and GUG at or near the 5 "-end direct the inclusion V-formylmethionine as V-terminal protein amino acid. We can say that these codons are specific initiators of protein synthesis. The most active codon is AUG.
Elongation (elongation) of the polypeptide chain is provided by elongation factors ef-tsand EF-Tu,as well as hydrolysis of one ATP molecule, and the movement of an mRNA molecule from one site of the ribosome to another is provided by the elongation factor EF-Gand hydrolysis of one GTP molecule. Each time the mRNA moves three nucleotides. In bacteria, the elongation rate is 16 amino acids per second. This means that ribosomes move along the mRNA at a rate of 48 nucleotides per second.
The termination (end) of synthesis is determined by the stop codons of the UAG, UAA and UGA. When one of these codons approaches the A site of the ribosome, the polypeptide, tRNA in the P site, and mRNA are released, and the ribosomal subunits dissociate. The end of protein synthesis is associated with the activity of protein factors - release RF1and RF2.Having dissociated, the ribosomal subunits begin to translate another mRNA molecule. Most of the mRNA is simultaneously translated by several ribosomes (polysomes). For example, a hemoglobin chain of 150 amino acids is synthesized at the pentaribosomal complex. In prokaryotes, synthesis and translation of mRNA occurs in the direction from the 5 "end to the 3" end. Further, they have no nuclear membrane. Therefore, translation of mRNA begins even before the completion of its synthesis. In contrast, in eukaryotes, transcription and translation are separated in time, since it takes time for mRNA to pass from the nucleus through the nuclear membrane into the cytoplasm.
MITOCHONDRIAL GENETIC CODE
In addition to the genetic code found in nuclear DNA, there is a genetic code found in mitochondrial DNA. We can say that as a result of the presence of a code in mitochondrial DNA, there is an independent apparatus for protein synthesis in mitochondria.
The mitochondrial genetic code is characterized by the same structure and properties and mechanisms of transcription and translation as in the case of the nuclear genetic code. However, specific differences are also known. Mitochondrial DNA of humans and other mammals contains 64 codons, of which 4 are stopcodons. The size of mitochondrial ribosomes varies greatly. In particular, the size of human mitochondrial ribosomes is 60 S.Studying the translation of mitochondrial genetic
the code made it possible to identify anticodons for 22 tRNAs, the number of which is 2.5 times less compared to the nuclear code (Table 14). However, each anticodon in the case of the mitochondrial genetic code is capable of pairing with several codons. For example, the UAH anticodon pairs with the codons CUU, CUC, CUA, and CUG, which encode leucine. 22 tRNA anticodons are paired with 60 mRNA codons.
Table 14.Anticodons in the mitochondrial genetic code of mammals *
GAA | phenylalanine | Gua tyrosine |
|
UAA | leucine | ||
UAG | leucine | GUG | histidine |
GAU | isoleucine | UUG | glutamine |
CAU | methionine | GUU | asparagine |
UAC | valine | Uuu | lysine |
UGA | series | GUTS | aspartic acid |
UGG | proline | UTC | glutamic acid |
USU | threonine | GCA | cysteine |
UHC | alanine | UCA | tryptophan |
UCH | arginine |
||
HCC | serine |
||
UCC glycine |
|||
* The GAA anticodon mates with the UUU and UUC codon, the UAA anticodon with the UUA and UUG codons, the UAG anticodon with the CUU, CUC, CUA and CUG codons, etc. ...
UNIVERSALITY AND ORIGIN
GENETIC CODE
The genetic code of nuclear DNA is universal, since it is the same for all living things, that is, all living things use the same sets of codons. The recognition of the universal character of the genetic code is an outstanding modern proof of the unity of the origin of organic forms.
Since the main features of the structure of the genetic code were determined, hypotheses were also formulated regarding
its evolution, and several such hypotheses are known to date. In accordance with one hypothesis, the original code (in a primitive cell) consisted of a very large number of ambiguous codons, which excluded the correct translation of genetic information. Therefore, in the process of evolution of organisms, the development of the genetic code proceeded along the line of reducing errors in translation, which led to the code in its modern form. On the contrary, according to another hypothesis, the code arose as a result of minimizing the lethal effects of mutations during evolution, and selective pressure led to the elimination of meaningless codons and to limiting the frequency of mutations in codons, changes in which were not accompanied by changes in the amino acid sequence or were accompanied by substitutions of only one amino acid by another, but functionally related. Having developed in the process of evolution, the code once became "frozen", that is, the way we see it now.
In accordance with the third hypothesis, it is assumed that the early archetypal code was a doublet, consisted of 16 doublet codons. Each of the 15 doublets encoded each of the 15 amino acids, of which, probably, the proteins of the primitive cell were composed, while the 16th doublet remaining free provided a free space ("gap") between genes. The triplet code appeared when the remaining 5 amino acids were formed in the process of evolution, and its appearance is associated with the addition of a third base to each codon.
It is believed that the modern genetic code is the result of a long evolution of a primitive code that encoded only a few amino acids, moreover, only a few triplets composed of two types of nitrogenous bases. Subsequently, the evolution of the code consisted in reducing the number of meaningless triplets and increasing the number of semantic ones. This led to the fact that most of the triplets began to be "read". The final stage in the evolution of the code was associated with an increase in the number of amino acids subject to "recognition" by the corresponding nucleotides (triplets), as well as with the synthesis of the corresponding tRNA and activating enzymes by the cells. When the number and structure of proteins became such that no new amino acid could improve the selective advantages of organisms, the code "froze" in its modern form.
As for the mitochondrial code, it is considered more primitive than the nuclear one. It is assumed that, for example, the anticodon UAA in the modern mitochondrial code could also be the anticodon of the archetypal code for codons in which the first two bases are Y, and the third could be Y, C, A, or G. But it can be assumed that the mitochondrial the code arose as a result of simplification in connection with the origin of mitochondria, the features of protein synthesis in the latter.
As you can see, modern views on the origin and evolution of the code are still contradictory, because there are still no experimental data that could be used to sufficiently substantiate one or another hypothesis.
MUTATIONS
Mutations (from lat. mutatio -change) - these are changes in genes and chromosomes, phenotypically manifested in a change in the properties and characteristics of organisms. Mutagenesis is a process of mutation formation in time and space.
Mutations are characteristic of all living things, including humans, in whom they are accompanied by hereditary diseases. Mutant organisms can differ from the original (wild-type organisms) in a variety of properties - morphological, physiological, biochemical, etc. For example, in microorganisms, mutations are accompanied by a change in the shape of colonies, nutritional needs, attitude to medicinal substances, etc. In insects, mutants differ from the original organisms in the shape and color of the body, wings, limbs, eyes, reaction to light, serological properties, etc. In humans, mutations lead to various deviations from the norm and are accompanied by hereditary pathology (see Chapter VIII). But it is important to remember that mutants remain the same species as the wild-type organism from which they originated.
Mutations should be distinguished from phenocopy, which is produced by environmental factors. By mimicking the action of genes, they are not inherited. For example, if pregnant mice are exposed to a reduced atmospheric pressure, then some of the individuals in the droppings of such mice will have damage in the urinary tract, but not inherited, however. In the case of human
Mutations occur at all stages individual development organisms and infect genes and chromosomes both in germ cells, both before fertilization and after fertilization (after the first division of fertilized eggs), and in somatic ones, and in any phase of the cell cycle. Therefore, according to the type of cells in which mutations occur, generative and somatic mutations are distinguished (respectively).
Generative mutations occur in genital and germ cells. If a mutation (generative) is carried out in genital cells, then several gametes can get the mutant gene at once, which will increase the potential for the inheritance of this mutation by several individuals (individuals) in the offspring. If the mutation occurs in a gamete, then probably only one individual (individual) in the offspring will receive this gene. The frequency of mutations in germ cells is influenced by the age of the organism.
Somatic mutations are found in somatic cells of organisms. In animals and humans, mutational changes will persist only in these cells. But in plants, due to their ability to vegetatively reproduce, the mutation can go beyond the limits of somatic tissues. For example, the famous winter apple variety "Delicious" originates from a mutation in a somatic cell, which, as a result of division, led to the formation of a branch that had the characteristics of a mutant type. This was followed by vegetative propagation, which made it possible to obtain plants with the properties of this variety.
The type of inheritance is distinguished dominant, semi-dominant, codominantand recessivemutations. Dominant mutations are characterized by a direct effect on the body, semi-dominant mutations consist in the fact that the heterozygous form in phenotype is intermediate between the forms AAand aa,and codominant mutations are characterized by the fact that heterozygotes A 1 A 2signs of both alleles appear. Recessive mutations are absent in heterozygotes.
If a dominant mutation occurs in gametes, its effects are expressed directly in the offspring. Many mutations in humans are dominant. They are common in animals and plants.
For example, a generative dominant mutation gave rise to the Ancona breed of short-legged sheep.
An example of a semi-dominant mutation is the mutational formation of a heterozygous form Aa,intermediate in phenotype between organisms AAand aa.This occurs in the case of biochemical traits, when the contribution of both alleles to the trait is the same.
An example of a codominant mutation are alleles 1 A and 1 B, which determine blood group IV in humans.
When recessive mutations their effects are hidden in diploids. They appear only in a homozygous state. An example is the recessive mutations that determine human gene diseases.
Thus, not only the stage of the reproductive cycle, but also the dominance of the mutant allele are among the main factors in determining the likelihood of the manifestation of a mutant allele in an organism and a population.
Depending on the localization in the cells, there are gene (point)and chromosomalmutations (Fig. 56).
IMUTATIONSI

Figure: 56.Classification of mutations
Gene mutationsconsist in changes in individual genes. Therefore, they are also called point mutations and are classified into single-site and multi-site. A single-site mutation affects one site, a multisite mutation affects several sites of the gene locus. Some sites are “hotspots” because concentrated mutations occur in them due to the presence of modified bases in the nucleotide sequences. The latter undergo frequent deamination, and this leads to changes in base sequences (see below).
Gene mutations are also classified into direct and reverse (reverse), which are equally found in organisms of all systematic groups.
Direct mutations- these are those that inactivate wild-type genes, that is, mutations that change the information encoded in DNA in a direct way, as a result of which the change from the original (wild) type organism goes to the mutant type organism.
Reverse mutations represent reversions to the original (wild) types from the mutant. These reversions are of two types. The former are caused by repeated mutations of a similar site or locus and are called true reversible mutations. The second reversions are mutations in some other gene that change the expression of the mutant gene towards the original type, i.e., the damage in the mutant gene is preserved, but it seems to restore its function. Such restoration (complete or partial) of the phenotype, despite the preservation of the original genetic damage (mutation), is called suppression, and reverse mutations are called suppressive (extragenic). As a rule, suppression occurs as a result of mutations in genes encoding the synthesis of tRNA and ribosomes.
Most genes are quite resistant to mutation, however, genes are known that mutate very often.
Spontaneous substitutions of nitrogenous bases occur in DNA as a result of "mistakes" made by DNA polymerase and accompanied by incorrect base pairing. One of the explanations for this "error" was given by D. Watson and F. Crick back in 1953 and comes down to the recognition of the role of automeric forms (structures in which the proton has moved to the place opposite to the usual hydrogen bond) of natural bases in erroneous pairing.
niy. Therefore, natural base tautomers provide the structural basis for base substitution mutations.
Chromosomal mutations associated with changes in the number and structure of chromosomes.
Changes in the number of chromosomes are determined by the addition or reduction of the entire set of chromosomes, leading to polyploidy or haploidy (respectively), as well as the addition or removal of one or more chromosomes from the set, which leads to heteroploidy or aneuploidy (monosomy, trisomy, and other polysomies), while changes in the structure of chromosomes are determined by rearrangements (aberrations) of their structure.
Polyploidyis a chromosomal mutation in the form of an increase in the number of complete haploid sets of chromosomes. In polyploids, each chromosome is represented by more than two homologues. Triploidy (3i), tetraploidy (4n), pentaploidy (5i), etc. are known. Most often polyploidy occurs in plants, since they are characterized by hermaphroditism and apomixis. Almost one third of all wild flowering plant species are polyploids. Polyploids of various wheat species are typical, in which the somatic numbers 2n - 14, 28 and 42 with the main gamete number n\u003d 7. Polyploids include potatoes, tobacco, white clover, alfalfa and other plants. Related species, the sets of chromosomes of which represent a series of increasing (multiple) increases in the main number of chromosomes, constitute polyploid series.
Polyploids originating from similar diploid organisms are called autopolyploids. Artificial polyploids obtained from hybrids of diploid plants belonging to far-apart species are called allopolyploids. Both autopolyploids and allopolyploids are found in nature, but the geographical distribution of polyploids usually differs from the distribution of their diploid "relatives". For example, the flora of the island of Svalbard contains a very high percentage of polyploid rows, while in other places their number is less compared to diploids. Plant polyploidy has economic value (increased fruit size, high sugar content, better preservation, etc.).
In animals, polyploidy is very rare. It is found in earthworms that reproduce parthenogenetically (polyploid series with the main numbers 11, 16, 17, 18 and 19 chromo
catfish), in some arthropods, fish and amphibians. In particular, it has been described in marine shrimp. Female salamanders of certain species, which have large red blood cells with nuclei, produce triploid larvae with 42 chromosomes, while salamanders with small nuclear red blood cells produce diploid larvae with 28 chromosomes. All Pacific salmonids are polyploids.
Syrian hamster (Mesocricetius awantus),in which 2n \u003d 44, is an allopolyploid resulting from natural hybridization between a European hamster (Cricetus 2p \u003d22), and a hamster belonging to one of the Asian species (Cricetus griseus, 2p -24).
Polyploidy also occurs in humans during the prenatal period of development. In particular, there are many reports of the discovery of triploidy and tetraploidy in abortion cells. The available data suggest that triploidy occurs in 20% of abortions, and tetraploidy - in 6% of abortions.
The rarity of polyploidy in dioecious animals, apparently, is determined by the fact that it violates the normal ratio of autosomes and sex chromosomes in zygotes.
In addition to auto- and allopolyploidy, endopolyploidy has been established in the somatic cells of a number of multicellular organisms, which is characterized by an increase in the number of chromosomes in the resting nucleus (in the absence of mitysis). Pseudopolyploidy of individual plants and insects should be distinguished from polyploidy, resulting from single or multiple division of genome components, when centromeres are diffuse in nature.
Haploidyis a mutation in the form of a decrease in the entire set of chromosomes. Found mainly in plants of over 800 species (wheat, corn, etc.). It is very rare in animals; it is unknown in humans.
A mutation in the form of violations of the normal number of chromosomes due to the addition or removal of one or more chromosomes in a chromosome pair is called heteroploidyor aneuploidy.Among heteroploids, polysomies are known, when any pair of chromosomes becomes triplicate or more monosomies, when a chromosomal pair loses one homologue, and nullsomies, when the entire chromosomal pair is lost. These mutations are widespread in both animals and plants. In particular, trisomies and monosomies have been found in humans, dogs and other animals, as well as
in many fruit, grain and vegetable plants. Trisomy, like monosomy, is often found in abortion cells.
Mutations that affect the structure of chromosomes are called chromosomal rearrangements, or more often aberrations. Among the mutations affecting the structure of chromosomes, there are deletions, duplications, inversions and translocations (Fig. 57).

Figure: 57.Chromosomal aberrations: 1 - normal chromosome; 2 - deletion; 3 - duplications; 4 - heterozygous translocations; 5 - heterozygous inversions; 6 - homozygous translocations; 7 - homozygous inversions. Centromeres are shown in large dark zones.
Deletionsare the loss of a segment of a chromosome carrying one or more genes. They are the most common and dangerous form of genetic macrodamage for humans. Large
deletions involve the loss of one or more genes and even gene blocks. In haploid organisms, large deletions are lethal. The deletion effect in diploid organisms depends on the number of deleted genes, the quantitative requirements for the products of the affected genes, the position of genes among functionally coordinated gene groups, etc. In diploid cells or in organisms homozygous for a given deletion, the latter is lethal.
Duplications(additions) are additions (lengthenings) of a segment of a chromosome carrying one or more genes, as a result of the fact that the same segment of a chromosome can be repeated several times. This repeat can be small, affecting a single gene, or large, affecting a large number of genes. Duplicates are often harmless to their media. It is believed that they contribute to the formation of polygenes or are a way of introducing new genes into genomes. Some duplications, however, are harmful and even lethal (see Chapter VIII).
Inversionsare in turns 180? segments released as a result of paired breaks in chromosomes. If the inverted segment does not contain a centromere, this mutation is called paracentric inversion; if such a segment contains a centromere, this mutation is called pericentric. Inversions affect meiosis, resulting in reduced fertility in hybrids. Some hereditary anomalies caused by this mutation are described (see Chapter VIII).
Translocation -it is an exchange of parts (segments) of homologous and non-homologous chromosomes formed by breaks along the length of the latter. Translocated segments can be of different sizes - from small to large.
Depending on the origin, spontaneous and induced gene and chromosomal mutations are distinguished.
Spontaneousare called gene and chromosomal mutations that occur in normal (natural) conditions, at first glance, for no apparent reason, while inducedrefers to those mutations that result from exposure of cells (organisms) to mutagenic factors.
Spontaneous mutations arise spontaneously and have a random (undirected) character in time and space. The most significant feature of these mutations is that they probably arise under natural radioactive conditions.
active background of the Earth (cosmic radiation, radioactive elements on the Earth's surface, radionuclides incorporated into organisms) as a result of normal processes occurring in cells, in particular, as a result of replication errors, when a nucleotide is mistakenly included and at the same time there is a deficiency in " editing "mechanism, which excludes error correction. Errors can also be associated with chemical instability of nucleotides. For example, cytosine can be deaminated to uracil, which is then recognized as thymine during DNA replication. Their frequencies in organisms of all types are extremely low. Determination of the frequencies of spontaneous mutations in organisms of different species is based on data on the average mutation frequencies at many sites and should reflect all changes in the DNA base sequences in the studied genetic region. In this case, the average mutation frequencies should be determined by measuring direct mutations within different genes, which are very sensitive to mutations, regardless of whether the conditions for organisms are restrictive or selective.
The frequency of spontaneous mutations is determined by comparing cells or populations of organisms treated and untreated with the mutagen. If the frequency of a mutation in a population is increased by a factor of 100 as a result of treatment with a mutagen, then it is considered that only one mutant in the population will be spontaneous.
The frequencies of mutations for base pair replication and the total frequencies of point mutations in different organisms determined to date are shown in Table. fifteen.
Some genes are resistant to mutation, others mutate spontaneously more often, and still others so often that their carriers are mosaics of mutated and unmutated genes. There are genes that affect the ability to mutate other genes. Such genes are called mutator genes.
Induced are those mutations that arise after the treatment of cells (organisms) with mutagenic factors - physical, chemical and biological. Most of these factors either react directly with nitrogenous bases in DNA molecules, or are incorporated into nucleotide sequences.
Among physical mutagens, ionizing radiation and ultraviolet (UV) study are distinguished, which are part of the electromagnetic spectrum that contains waves that are shorter and with higher energy than visible light (below 0.1 nm).
Table 15.Frequencies of mutations of different organisms
Organism | Number of base pairs per genome | Frequency of mutations per base pair replication | Total mutation frequency |
PhageT4 | 1,8 ? 10 6 | 1,7 ? 10 -3 | 3,0 ? 10 -3 |
E. coli | 4,5 ? 10 6 | 2,0 ? 10 -10 | 0,9 ? 10 -3 |
N. crassa | 4,5 ? 10 7 | 0,7 ? 10 -11 | 2,9 ? 10 -4 |
D. melanogaster | 2,0 ? 10 8 | 7,0 ? 10 -11 |
Ionizing radiation - these are X-rays (X-rays), protons and neutrons, as well as α, β and γ-rays released by radioactive isotopes (32 P, 14 C, 3 H, cobalt-90, etc.). They are highly energetic and can penetrate tissues in which they collide with atoms and cause the release of electrons, leaving positively charged free radicals or ions. In turn, these ions collide with other molecules, causing further electrons to be released. Therefore, along the track of each high-energy beam, a rod of ions is formed, passing into living tissues.
The mutagenic effect of ionizing radiation is caused by the increased reactivity of atoms present in DNA. Ionizing radiation induces gene mutations (transitions, transversions, deletions, inclusions), as well as chromosomal breaks accompanied by translocations and other aberrations. In the case of acute irradiation of a person, most of the spermatogonia die, but the spermatocytes survive, as a result of which a decrease in fertility occurs in the first 6 weeks after irradiation, followed by infertility (2-3 months). Protection must be provided for several weeks before and after conception.
X-ray diagnostics and X-ray therapy of the abdominal cavity and pelvic region are of great danger. Therefore, conception within a few weeks before and after irradiation should be ruled out.
For a person, a doubling dose ionizing radiation for gene mutations is 1 gray, for chromosomal aberrations (translocations) - 0.15 gray. A characteristic feature of ionizing radiation is also the fact that there is no threshold for it in the dose, as well as the fact that it has a communicative effect.
Ultraviolet radiation it is characterized by less energy, penetrates only through the surface layers of cells of animals and plants and does not cause tissue ionization. The mutagenic effects of UV radiation are also caused by the increased reactivity of atoms present in DNA molecules. It is not dangerous for human germ cells, as it is absorbed by the skin. UV radiation promotes the formation of thymine dimers in skin cells, the mutagenic effect of which is that they cause mutations not directly, but by impairing the accuracy of DNA replication.
Chemical mutagens are organic and inorganic acids, alkalis, peroxides, metal salts, ethylene amines, formaldehydes, phenols, acridine dyes, alkylating compounds, analogs of purine and pyrimidine bases, etc. In particular, there are known analogs of bases (5-bromouracil, 2-aminopurine), chemical factors which change the structure and base pairing (nitrous acid, nitrosoguanidine, methyl methanesulfate, ethyl methanesulfonate, intercalating agents (acridine orange, proflavine, ethidium bromide), agents that change the structure of DNA (psoralen, peroxides) (form. 9), It is believed that for action chemical mutagens are characterized by a threshold. Some chemical mutagens act on both replicating and resting DNA, while others only on replicating DNA. and nitrous acid.To mutagens affecting replication curing DNA include analogs of nitrogenous bases and acridine dyes.
Many chemical mutagens disrupt meiosis, resulting in chromosome nondisjunction, as well as chromosome breaks and gene mutations. For example, trypoflavin acts at all stages of germ cell development, nitrosoguanidine - before meiosis, and treninon - after meiosis.
Some of the chemical non-mutagenic compounds become mutagens when ingested, such as cyclophosphamide.
Noteworthy are the chemicals used as medicinal compounds. Thus, after treatment with alkylating compounds, conception should be avoided in the first three months. There are known indications of mutagenicity of oral chemical

Formula 9
contraceptives, as well as some compounds found in cosmetics and food preservatives.
Biological mutagens are viruses that cause chromosomal aberrations, as well as transposable genetic elements that cause gene and chromosomal mutations.
Experimental work uses different methods for obtaining site-directed induced mutations. In particular, mutagenesis is widespread in vitrocloned DNA. For this, the latter is treated with nucleases or chemical mutagens. In addition, methods of mutagenesis of chemically synthesized DNA are known. Finally, it is possible to obtain chromosomal aberrations in stem cells by a genetic engineering method.
Genetic imprinting differs significantly from mutations, in which gene expression depends on parental origin. Imprinting genes are found in regions of chromosomes with differences in alleles. Unlike mutations, genetic imprinting alters the regulation of genes.
a set of chromosomes leading to diploid gametes. Non-divergence in women is noted in 80% of cases, and in men - in 20% of cases, both in the first and in the second meiotic division.
The mechanisms of heteroploidy are associated with breaks in chromosomes or chromatids and consist in changes in the sequence of gene loci on chromosomes. In humans, trisomies are explained by the nondisjunction of chromosomes in both the first and second meiotic division.
The molecular mechanisms of chromosomal mutations require additional research.
The molecular mechanisms of gene mutations consist in changes in the sequence of nitrogenous bases in DNA molecules. These changes occur as a result of substitutions, deletions (deletions), inclusions and duplications of bases.
Changes associated with the substitution of bases are classified into simple and cross substitutions (Table 16).
Table 16.Types of base substitutions
Initial base | The base that took the place of the original | Replacement type |
Pudding | Another purine | Simple replacement (transit) |
Pyrimidine | Another pyrimidine | Also |
Pudding | Any pyrimidine | Cross replacement (transversion) |
Pyrimidine | Any purine | Also |
Simple substitutions, or transitions, consist in replacing purine with purine and vice versa, and in a double-stranded DNA pair molecule ATfor a couple G-Cand vice versa. Transitions occur during DNA replication without changing the orientation of the purine-pyrimidine in the double-stranded molecule.
Cross substitutions, or transversions, are linked by the replacement of purine with pyrimidine in the DNA and vice versa. The substitution pyrimidine pairs with purine, so that a pyrimidine-purine pair appears in the double-stranded DNA molecule instead of a purine-pyrimidine pair. Consequently, transversions lead to new orientations of the purine-pyrimidine pairs and consist in the replacement of the pair in the double-stranded DNA molecule ATfor a couple C-Gand vice versa; couples ATfor a couple T-Aand vice versa; couples T-Afor a couple G-Cand vice versa, as well as pairs G-Cfor a couple C-Gand vice versa.
Spontaneous substitutions of nitrogenous bases are very rare. For example, according to existing calculations, about 10-20 spontaneous base substitutions occur in humans per year, and one substitution can be repeated for every 10,000 genes only 50 times over a period of 1 million years. It can be assumed that such an extremely low frequency of base substitutions in DNA is inherent in both animals (mammals) and humans.
DNA bases undergo spontaneous structural changes called tautomerization, which can exist in two forms; for example, guanine can be in keto or enolic forms (Form 10).
Spontaneous substitutions of nitrogenous bases occur in DNA as a result of “mistakes” made by DNA polymerase, and are accompanied by incorrect base pairing. One of the explanations for this "fallacy" was given by D. Watson and F. Crick back in 1953. It boils down to the recognition of the role of tautomeric forms (structures in which the proton has passed to the place opposite to the hydrogen bond) of natural bases in "mistaken pairing". Therefore, the natural base tautomers provide the structural basis for base substitution mutations.
Transitions are induced by nitrous acid, which causes oxidative deaminationadenine, cytosine and guanine containing free amino groups into hypoxanthine, uracil and xanthine, respectively. Since deamination is accompanied by the transition of the amino base to the ketone base, hypoxanthine, for example, like guanine, will pair with cytosine, i.e., as a result of deamination of adenine into hypoxanthine vapor ATwill pair up G-C.In the case of deamination of cytosine into uracil vapor G-Cwill pair up AT(form. 11). Transitions are also induced by alkylating compounds. For example, ethyl methanesulfonate alkylates guanine and frees DNA from it without disrupting its sugar-phosphate backbone. Consequently, guanine can be replaced by any base, and this leads not only to transitions, but also transversions.
Finally, transitions are caused by mutagens that act on DNA only in a state of replication. For example, 5-bromouracil, which is an analogue of thymine and is able to be incorporated into DNA through thymine substitution. Along with the normal ability of 5-bromouracil to mate with adenine, a condition sometimes occurs when it acts not as thymine, but as cytosine,

which ensures the formation of its hydrogen bonds not with adenine, but with guanine. These pairing "errors" occur either when 5-bromouracil is incorporated into DNA (inclusion "errors"), or
when DNA replicates after it is turned on (replication "errors"). Consequently, the time of "errors" determines the nature of the transition. Mating "errors" induced by 5-bromouracil lead to transitions from the pair G-Cto couple ATand vice versa (from ATto G-C).Similar transitions are also induced by 2-aminopurine.

CH,
Formula 11
Base substitutions lead to changes in the meaning of codons, as a result of which they acquire the ability to encode another amino acid (missense mutations).For example, the substitution in the triplet of GUA contained in the β-hemoglobin gene of uracil for adenine (transversion) is accompanied by the fact that glutamic acid appears in the β-hemoglobin chain instead of valine. This leads to the conversion of hemoglobin into a new variant of mutant hemoglobin (for example, of the Bristol type). Substitutions of bases also result in nonsense mutations,when the reading of gene information is interrupted on the changed codons (as a rule, such codons are the UAG, UAA and UGA triplets). At the same time, as a result of substitutions, codons are formed that retain the original meaning.
Substitutions can occur in introns or in regions where transcription, translation, and splicing are regulated.
Deletions and insertions of one or more nitrogenous bases in DNA nucleotide sequences can be DNA replication errors or be induced by acridine dyes. Such changes are called frame shift mutations,for they lead to a shift in the "reading frame" of the gene code. Turning on between adjacent bases, acridine orange makes them "move apart" at a distance of 6-8AND.If acridine orange is present in the template polynucleotide strand, the result will be the addition of a base to the new strand during DNA replication. If acridine orange is present during replication, it can be incorporated into a new strand instead of a base, masking the opposite base in the template strand, and then exit. This leads to the fact that the newly replicated strand will be lacking a base, i.e., it will be replicated with a base deletion. Deletions can affect several bases. For example, deletions of 15 nucleotides lead to a loss of 5 amino acids in the protein.
Duplications (addition) of 1-2 bases can also lead to mutations with a shift in the "reading frame". If duplications occur within a gene, then the "reading frame" of the code is disrupted over a large extent.
Repeats of triplet nitrogenous bases represent a special form of molecular mechanisms of gene mutations. The presence of base triplets repeats in DNA molecules is accompanied by disruptions in the normal DNA replication cycle by abnormal protein synthesis (due to repetitions of the amino acid encoded by the repeated triplet). For example, mutations in the gene that controls the Huntington protein, the lack of which in humans is accompanied by Huntington's disease, is a sharp increase in the repeats of the CAG triplet.
Deletions and duplications of nitrogenous bases represent the molecular mechanism and mutations of human mitochondrial DNA. It has been found that segments of about 5000 base pairs can be deleted from mtDNA.
Mutations can alter normal imprinting. Imprinting occurs in many regions of chromosomes.
RESTORING DNA DAMAGE
The mutagenic and lethal effects of mutagens are due to the structural damage they cause in molecules
DNA. However, this damage is often recoverable. The process of repairing DNA damage is called DNA repair or repair.
Being sensitive to one or another type of radiation, cells react to UV irradiation by the fact that damage is formed in their DNA, the main ones of which are photochemical changes in pyrimidine bases, passing into pyrimidine dimers, in particular thymine. The latter are formed due to covalently linked adjacent thymine bases in the same chain of the molecule through the addition of carbon to carbon. In addition to thymine dimers, cytosine-thymine and cytosine-cytosine dimers are also formed in the DNA of irradiated cells, but their frequency is lower. Dimerization of flanking bases in a gene is accompanied by obstruction of transcription. It also leads to mutations. As a result, the cell may die or undergo malignancy.
One of the mechanisms for repairing DNA damage operates in many types of organisms, including humans, and consists in the fact that exposure to visible light of cells pretreated with UV radiation leads to a decrease in the lethal effect by several times, i.e., to the reactivation of the functions of the irradiated cells. This reactivating effect of visible light is associated with the cleavage (monomerization) of pyrimidine dimers, and this process is provided by a light-dependent photoreactivating enzyme
(fig. 58).
Another mechanism for the removal of pyrimidine base dimers from the DNA of irradiated cells is called dark repair or excision-restoration. As well as photoreactivation, it is an enzymatic process, but more complex, moreover, taking place in the dark (Fig. 59). This mechanism consists in the fact that thymine dimers undergo “excision” from the DNA strand, in which “gaps” remain, “plugged” by DNA repair synthesis with the participation of DNA polymerase and using the opposite strand as a template. The final stage in the removal of pyrimidine dimers from DNA-irradiated cells by “excision” and “patching” of the “gaps” consists in the closure of the newly replicated DNA region with adjacent damaged areas and “patching” of sugar-phosphate skeletal bonds by means of the DNA ligase enzyme.
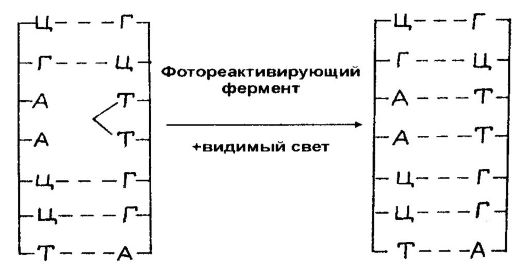
Figure: 58.Photoreactivation of UV-Induced Pyrimidine Dimers in the Presence of Visible Light
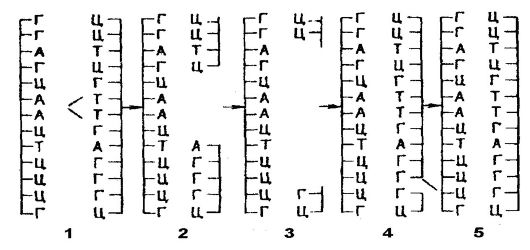
Figure: 59.Excision of pyrimidine dimers from DNA, induced by
UV radiation: 1 - thymine dimer; 2 - "gap" in the chain; 3 - expansion of the "gap"; 4 - filling the "gap" with reductive synthesis; 5 - "blurring" a single-strand breakThe third mechanism for repairing DNA damage is called post-replication or recombination repair (Fig. 60). It consists in the fact that DNA synthesis in UV-irradiated cells proceeds at a normal rate along the chromosome only up to the dimer, before which it slows down for several seconds, after which it starts again, but on the other side of the dimer. Since DNA polymerase jumps over the dimer, a "gap" is formed in the daughter chain. As a consequence, the region containing the dimer in one duplex will be intact in the sister duplex, i.e., in the daughter
in DNA molecules, one strand contains pyrimidine dimers, while the other contains gaps, which are actually secondary damage. Consequently, the region containing dimers in one duplex is completely preserved in the sister duplex. This process ends with recombination along the DNA molecule after its replication, in which a daughter strand carrying a "gap" in some part is paired with another daughter strand (complementary), carrying a "gap" elsewhere. This pairing allows reconstructive synthesis to ensure that the correct sequence of the region is restored in each gap. The corresponding intact region of another child chain is used as a template. Recombination events at the level of each "gap" lead to the reconstruction of an intact DNA molecule capable of further replication.

Figure: 60.Post-replication DNA repair: 1 - damaged base; 2 - point of DNA replication; 3 - "gap"; 4 - recombination between daughter chromosomes; 5 - complete DNA repair (but the damaged base remains)
In humans, the syndrome "xeroderma pigmentosum" is known, which is characterized by extreme sensitivity of the skin to sunlight, as a result of which it undergoes excessive pigmentation, and then often malignant skin cells. The onset of this syndrome is associated with a defect in the ability to cut thymine dimers from DNA. Bloom's syndrome is also known, which consists in the increased sensitivity of individuals
to sunlight and associated with increased sister chromatid exchanges in their genomes. This syndrome is also associated with a defect in DNA repair.
Normally, DNA damage induced by sunlight (UV component) is repaired by cut-repair.
Some of the potentially lethal or secondary damage induced by X-ray radiation can be repaired by recombination or some other mechanism in which recombinase enzymes are involved. It is also assumed that, in contrast to DNA damage induced by UV radiation, damage induced by X-ray radiation is susceptible to repair (via recombination) even before the first post-radiation replication.
Damage caused by chemical mutagens in DNA is also repaired by one mechanism or another. Each of the DNA repair mechanisms is essentially a DNA defense system. At the same time, DNA repair is often accompanied by errors that manifest themselves in the form of mutations.
Despite the fact that DNA is the custodian of genetic information, it has limited chemical stability. Hydrolysis, oxidation, and nonenzymatic DNA methylation occur in cells with a fairly high frequency. These reactions interact with DNA repair. It is believed that spontaneous DNA decay is a major factor in spontaneous mutagenesis, carcinogenesis, and old age.
DNA is likely to code for correcting its own mistakes.
GENETIC CONTROL OF GENE EXPRESSION
Information on the regulatory mechanisms of gene expression was obtained, for the most part, as a result of radiation of the simplest sample of control of gene activity, which is control, which extends to the sequence of reactions in biosynthesis carried out by microorganisms. Two mechanisms are known, one of which controls the activity of enzymes, while the second synthesizes enzymes (synthesis of specific proteins).
The essence of the control (regulation) of enzyme activity is illustrated by an example of isoleucine biosynthesis, an early
the origin of which is threonine and the conversion of which into isoleucine is carried out as a result of five consecutive reactions with the participation of enzymes. If isoleucine is added to the culture of bacteria that have an independent ability to synthesize amino acids, including isoleucine, this will lead to the cessation of the synthesis of this amino acid by the cells. The growth requirements of cells at this time are provided only by exogenous isoleucine. The mechanism of this phenomenon is the inhibition (suppression) of the activity of the enzyme catalyzing the conversion of threonine into the subsequent isoleucine precursor. The synthesis is restored only when exogenous isoleucine is depleted in the environment.
The uniqueness of this phenomenon is due to the fact that the inhibitor (end product) and the normal substrate have different structures and do not compete for the same binding site on the enzyme. It can be said that the enzyme carries two binding sites, one of which is specific for the substrate, the other for the inhibitor. Normally, the substrate attaches to the active site of the enzyme. However, if an inhibitor is attached to this specific site, then a structural transformation (transition) in the enzyme occurs, as a result of which the normal substrate is no longer attached, which blocks the activity of the enzyme that catalyzes the end of biosynthesis, or one of its stages. This phenomenon is called allosteric transition(fig. 61).
The allosteric interaction is based on any change in enzyme activity caused by selective binding at the second site of the enzyme, and this site does not overlap the site on the enzyme for binding the substrate. The enzyme essentially becomes a chemical transducer, allowing interaction between two molecules, an inhibitor and a substrate, that is otherwise eliminated. Certain enzymes are sensitive to activation when combined with an effector molecule other than the catalytic substrate. In addition, certain enzymes are susceptible to being activated by one metabolite and suppressed by another. Since mutations are possible that can affect one inhibitory site without affecting another, they phenotypically manifest themselves in the resistance of cells to inhibition by the final product and in the production of large amounts of the final product. Thus, allosteric transition
provides an extremely flexible system for regulating enzyme activity.
Figure: 61.Allosteric transition: and -active enzyme:
1 - the active center of the enzyme to which the substrate 3 is attached;
2 - active center of the enzyme, to which inhibitor 4 is attached;
b -inactive enzyme: 1 - modified active center
The synthesis of enzymes is regulated by the induction and repression of enzymes, which consist in stimulating or suppressing the synthesis of specific enzymes as a response to the addition of a component to the medium that increases the concentration of the effector in the cell.
An example of enzyme induction is the case of bacterial enzymes that utilize lactose. The bacteria acquire the ability to ferment lactose after some cultivation in the presence of this carbohydrate. This is determined by their synthesis of β-galactosidase, which breaks down lactose or another β-galactoside, as well as β-galactoside permease and β-galactoside transacetylase, which ensure the penetration of the substrate into the cell. Consequently, lactose induces the synthesis of enzymes, and this synthesis is coordinated.
An example of enzyme repression is the synthesis of tryptophan, which is formed from anthranilic acid with the participation of anthranilate synthetase. If the bacteria are sown in an environment that contains NH 4 Cl and glucose as a source of nitrogen and carbon, respectively, they grow very well and independently synthesize tryptophan (like other amino acids). But if exogenous tryptophan is added to the medium, then the bacteria stop synthesizing this amino acid. It is important to note that adding tryptophan
stops the synthesis of all enzymes involved in its biosynthesis. Thus, the final product inhibits all biosynthesis.
Based on data on the induction and repression of proteins, the French scientists F. Jacob and J. Monod (1961) formulated a model for the genetic control of protein synthesis; its components are genes for structure, regulation and operator genes, as well as a cytoplasmic repressor. According to this model, the molecular structure of proteins is determined by structure genes, the primary product of which is mRNA. The synthesis of mRNA can be started only at a certain point in the DNA chain (operator), on which the transcription of several linked structural genes can also depend. A group of genes whose transcriptional activity is coordinated by a single operator is operon,which is the unit of primary transcription and the unit of coordinated gene expression. There are also regulatory genes. Under the control of one or another regulator gene, a cytoplasmic repressor factor is produced, which has a reversible ability to bind to a specific operator. Due to this binding, the combination of a repressor and an operator blocks the initiation of transcription of the entire operon (mRNA formation), controlled by the operator, and therefore prevents the synthesis of proteins controlled by structural genes belonging to the operon.
A repressor has the ability to specifically bind (react) with small molecules (effectors). In the case of inducible enzyme systems, the repressor binds to the operator and blocks the transcription of the operon. The presence of an effector (inducer) binds (inactivates) the repressor, and this causes the transcription and translation of the operon genes to occur. In other words, the repressor connected to the effector loses its affinity to the operator and does not bind to it, and this is accompanied by the activation of the operon. In the case of repressive enzymes, the repressor itself is inactive, i.e., it has no relation to the operator and does not block transcription of the operon. It is activated only as a result of a combination (connection) with the final product in biosynthesis, as a result of which it blocks the transcription of the operon. Consequently, transcription of the operon occurs in the absence of an effector (end product), while the presence of an effector is accompanied by inhibition of the operon.
Regulatory mechanisms in the case of inducible and repressive systems are negative, since they suppress
synthesis of specific proteins. The regulatory mechanism operates on genetic levelby controlling the frequency of mRNA synthesis.
Operons are classified into catabolizing (inducible)and synthesizing (repressive).An example of catabolizing operons is the lactose operon (Fig. 62), which includes structural genes z, yand and,encoding (β-galactosidase, (β-permease and (β-transacetylase, respectively, the regulator gene /, encoding the synthesis of the repressor (protein mm 37 200, consisting of four identical units containing 347 amino acid residues), prototype), to which RNA polymerase is attached, and an operator gene that controls the functioning of structural genes The mechanism of regulation of the lactose operon is that in the absence of an inducer (lactose) the repressor is active, that is, it is associated with an operator, and this blocks the transcription of polygenic mRNA. In the presence of an inducer in the medium, the repressor loses its activity, i.e., it binds

Figure: 62.Lactose operon and its regulation
with an inductor, as a result of which the operator becomes free (unblocked) and mRNA transcription occurs. Therefore, the lactose operon is negatively controlled by controlling the frequency of mRNA synthesis.
However, positive regulation of the lactose operon is also possible. If, after the inductor, glucose is added to the medium where the bacteria are grown, then catabolic repression of β-galactosidase occurs, accompanied by a decrease in the level of cyclic AMP. If exogenous cAMP is added to the culture, then catabolic repression is removed and the lactose operon will function normally. Thus, cAMP is a positive regulator (regulation occurs in the presence of an inducer).
An example of a biosynthetic operon is the tryptophan operon (Fig. 63), the expression of which is under the negative control of the repressor - the product of the gene trp R.Repression by the end product means that the inactive repressor does not interfere with mRNA transcription. The repressor becomes active as a result of binding to the final product. When the complex repressor + final productbinds the operator, then this is accompanied by suppression of mRNA synthesis.
Genetic control of protein synthesis in prokaryotes occurs at the level of both transcription and translation and affects processes from mRNA synthesis to elongation of polypeptide chains (Fig. 64).

Figure: 63.Tryptophan operon

Figure: 64.Arabinose catabolism
The genome of eukaryotic cells contains a lot of regulator genes. Regulatory proteins, synthesized under the control of these genes, bind to a specific DNA sequence near the regulated genes.
For some organisms - eukaryotes (for example, microscopic fungi) - the operon organization of functionally related genes is also characteristic, however, in the case of most eukaryotes, it is believed that either they do not have operons, that is, eukaryotic genes are regulated individually, being transcribed into monocistronic mRNAs, or eukaryotic genes are regulated partly polycistronic, partly monocistronic. The second assumption is supported by data on the detection of C. elegansgenes organized into operons. In organisms of this type, the processing of polycistronic mRNA into monocistronic mRNA occurs before translation.
It is believed that genetic control of protein synthesis in higher eukaryotes is carried out both at the level of transcription (frequency of mRNA synthesis, mRNA processing, mRNA transport from the nucleus, mRNA stability), and at the translation level (translation frequency,
regulation of the synthesis of protein factors responsible for the initiation, elongation and termination of the polypeptide chain). It is also believed that the structure of chromatin is important in genetic regulation, which blocks the access of specific activating proteins (activators) to promoters. A specific complex has been established in eukaryotic cells, which provides ATP-dependent destruction of nucleosomes, while allowing activators to bind to the nucleosome core, which leads to transcription.
EVOLUTION OF GENES
Historically, the question of the evolution of genes is the most important, since the evolution of genes is associated with the origins of life in general and its improvement in particular. Since the initial role in the origin of life of RNA has been revealed, it is assumed that the beginning of the evolution of genes dates back to 3.5-3.8 billion years ago, when the first RNA molecules were formed, which somehow determined the synthesis of proteins, i.e., were the first custodians genetic information. However, when the need to improve the efficiency of protein synthesis emerged, the ability to encode genetic information passed to DNA, which became the main custodian of genetic information. As for RNA, it found itself between DNA and proteins, becoming a "carrier" of information. Of course, this hypothesis has no proof. Nevertheless, many believe that the appearance of DNA is associated with the complication of the structure of cells and, therefore, the need to encode a large amount of information in comparison with RNA. In other words, with the beginning of the participation of DNA in the storage of genetic information, the genetic code began to develop.
Recently, a hypothesis has received great attention, according to which the source of new genes is the recombination of exons, as well as transposons entering the genomes of organisms.
Of particular interest in evolutionary terms is DNA that is not transcribed (egoistic DNA). It seemed that there must be some counter-selection factors that ensure the maintenance of this DNA in cells. However, such factors are unknown. Nevertheless, it is a very popular assumption that selfish DNA is also the source of new genes.
In the discussion of the direction of evolution of genomes, two explanations are known. Some scientists suggest that the increase in cell genomes
in the process of evolution of organisms, it went through the inclusion of additional copies of genes in nuclear structures, while others believe that in evolution there was a duplication of already formed genes with their subsequent divergence. There is no evidence for the inclusion of genes in genomes, while the assumption of gene duplication and divergence has substantial rationales, and these rationales are based on the evidence that numerous families of proteins are encoded by sets of related genes.
It has been found, for example, that several genes are involved in the coding of chicken egg albumin. Human leukocyte interferon is encoded by nine non-allelic genes, and chick δ-crystallin - by two genes. The actin protein in insects and sea \u200b\u200burchins controlled by several genes, and for each actin in different contractile cells there is a gene. Chorionic proteins are also controlled by several genes, moreover, combined into a complex cluster. Several genes have been identified that encode rhodopsins, which provide the perception of different colors. Finally, immunoglobulins are also encoded by many genes, for example, in mice, three genes. Other examples are also known. Therefore, we can say that the synthesis of only a few proteins is controlled by single genes. For example, one genome encodes the synthesis of human and chicken insulin. In support of the assumption of gene duplication and divergence and, consequently, of the mechanisms of genome enlargement, data on the evolution of the multifamily of genes encoding hemoglobin are most indicative.
In marine worms, some insects and fish, the size of the oxygen-carrying globin molecule is only 150 amino acid residues. In humans, each hemoglobin molecule consists of two apolipeptide chains and two α-polypeptide chains. Hemoglobin synthesis is encoded by two unlinked gene clusters. The cluster of α-globin genes is localized on chromosome 16 and contains two embryonic and two almost identical fetal globin genes. The second cluster, located on chromosome 11, encodes β-globins. It consists of a β-globin gene, one embryonic β-gene, two fetal genes, and a β-globin gene.
Based on information about the genetic control of globins and sequencing data of globin genes, it is assumed that the very first duplication of a gene that controls the synthesis of a protein that is a precursor
nickname of hemoglobin, occurred 1 billion years ago, giving rise to a pair of genes. One gene from this pair in the course of evolution became the gene that controls the synthesis of myoglobin, the other developed into a gene that controls the synthesis of hemoglobin. Subsequently (about 500 million years ago), the hemoglobin gene underwent duplication again, resulting in the genes that control the synthesis of hemoglobin α and β chains. After some time, the β-chain gene underwent further duplication, which gave rise to the hemoglobin gene, synthesized only in the embryonic period. Further, the gene of embryonic hemoglobin also underwent duplication, which gave rise to hemoglobins ε and γ. Another duplication of the β-chain gene yielded a gene encoding β-globin synthesis. Thus, as a result of a series of tandem duplications, the initial globin gene became at one of the developmental stages clusters of α- and β-globin genes.
The evolution of genes is accelerated by transposable elements that have the ability to grow genomes. Finally, genetic recombination contributes to the increase in genomes.
One of the fundamental issues is related to the understanding of the mechanisms that prevent genes from duplication as a result of transcriptional activation of genes-“neighbors”. IN recent times For example D. melanogasterthe existence of borderline segments (sequences) of DNA, functionally isolating adjacent genes, is shown. The length of the insulator sequences is about 340 base pairs. It is possible that such sequences also exist in other organisms.
ISSUES FOR DISCUSSION
1. What is the basis of the idea that nucleic acids are genetic material? What is the significance of genetic engineering in the list of evidence for the genetic role of DNA?
2. Is there a relationship between the size of the genome (in the number of nucleotide pairs) and the species of the organism? Give examples to support your point of view.
3. What do you know about the ways of increasing the genome of cells in the process of development of organisms from lower to higher forms?
4. Determine the total length of DNA in human cells in centimeters.
5. DNA is stable at pH 11, but RNA is degraded to nucleotides by alkaline reaction. Using textbooks on biochemistry, explain the reason for this phenomenon.
6. If the β and β "subunits of RNA polymerase are 0.005 fractions of the total protein mass in cells E. coli,how many RNA polymerase molecules will there be in the cell, provided that each β and β "subunit is a whole molecule of this enzyme?
7. Why does urea denature RNA?
8. The composition of the bases (fraction G + C) of a double-stranded DNA molecule is reflected in the indicators of the floating density in cesium chloride and the melting point (Tn), at which half of the molecules "melt" into separate chains. It was found that the buoyant density is 1.660 + (0.098 χ fraction G + C), the fraction G + C \u003d 2.44 (T p - 69.3), and T p is determined in a standard saline solution. The buoyant DNA density of the rat is 1.702, D. teleanogaster -1,698 and yeast 1,699. Determine the G + C fraction and DNA melting point for each species.
9. What is the significance of human mitochondrial DNA?
10. What are the transposed genetic elements? How are they classified?
11. What are plasmids?
12. What are repetitive DNA sequences and how often are they repeated in the human genome?
13. What is the semi-conserved way of DNA replication and what is the biological significance of this way of replication?
14. What is the role of enzymes in DNA replication?
15. Is there a difference between DNA replication and chromosome replication?
16. What is a nucleosome and what are its sizes? What is the role of proteins in DNA packaging into chromosomes?
17. Calculate the number of nucleotide pairs in 1 megadalton of double-stranded DNA.
18. How many genes do you think there are in one human cell, given that the length of one gene is about 900 base pairs?
19. According to acid hydrolysis data, a DNA preparation isolated from cells of a stillborn human fetus was characterized by the following composition (in%): adenine - 25, thymine - 32, guanine - 22, cytosine - 21. How can this unusual result of the study be explained? guided by data on the structure of DNA?
20. What will be the length and total mass of DNA, if DNA molecules from all cells of a newborn child, whose organism consists of 2.5 χ 10 12 cells, are combined?
21. What are the Okazaki fragments and what is their role in DNA replication?
22. Can you name the experimental data confirming the antiparallel orientation of strands in the DNA molecule?
23. After denaturation, the DNA was annealed, allowing strands to rehybridize to 1% of their sequences. Then this DNA was treated with nuclease 1 until the molecules were completely digested, after which it was "dispersed" by electrophoresis in agarose gel. What are the results of electrophoresis?
24. How can one determine the genetic localization of / ^ / - sequences in the genome E. coli?
25. What are the molecular mechanisms of gene mutations?
26. Describe the mechanism of action of physical and chemical mutagens.
27. Can DNA damage be repaired and by what mechanisms? What is the role of repair mechanisms of DNA damage in mutagenesis?
28. What is the difference between enzyme induction and repression?
29. What is the concept of the operon and what is its significance in understanding the mechanisms of gene action?
30. At what levels of realization of genetic information is genetic control of gene expression carried out?
31. What determines the difficulties in studying the genetic regulation of gene action in eukaryotes?
32. How many types of RNA are involved in the biosynthesis of proteins and what is known about the nucleotide composition, chemical and physical properties of each type of RNA?
33. There is evidence in the scientific literature that 7-methylguanosine-5-monophosphate inhibits protein synthesis in the cell-free system, derived from reticulocytes. It is also known that 7-methylguanosine is present at the 5'-end of many mRNA molecules of eukaryotic cells. If you remove this group from mRNA (chemically) of the vesicular stomatitis virus, this does not prevent translation in the cell-free reticulacite system. ?
34. How do you understand the mechanism of genetic imprinting and what is its biological significance?